通常我使用shell命令time。我的目的是测试数据集是否小型、中型、大型或非常大型,需要多长时间和内存才能完成。
有没有适用于Linux或Python的工具来实现这个目的?
通常我使用shell命令time。我的目的是测试数据集是否小型、中型、大型或非常大型,需要多长时间和内存才能完成。
有没有适用于Linux或Python的工具来实现这个目的?
有几种方法可以对Python脚本进行基准测试。其中一种简单的方法是使用timeit模块,它提供了一种简单的方式来测量小代码片段的执行时间。然而,如果您正在寻找一个更全面的基准测试,包括内存使用情况,您可以使用memory_profiler包来测量内存使用情况。
为了可视化您的基准测试,您可以使用plotly库,它允许您创建交互式绘图。您可以创建一条线图来显示不同输入大小的执行时间和内存使用情况。
这里是一个例子代码片段,用于对以矩阵、行和列作为输入的函数的两个不同实现进行基准测试:
import timeit
import random
import numpy as np
from memory_profiler import memory_usage
from memory_profiler import profile
from plotly.subplots import make_subplots
import plotly.graph_objects as go
from memory_profiler import memory_usage
from memory_profiler import profile
from my.package.module import real_func_1, real_func_2
@profile
def func_impl_1(matrix, row, column):
return real_func_1(matrix, row, column)
@profile
def func_impl_2(matrix, row, column):
return real_func_2(matrix, row, column)
# Analysis range
x = list(range(3, 100))
# Time results
y1 = []
y2 = []
# Memory results
m1 = []
m2 = []
for i in x:
# Random choice of parameters
A = np.random.rand(i, i)
rx = random.randint(0, i-1)
ry = random.randint(0, i-1)
t1 = 0
t2 = 0
m1_ = 0
m2_ = 0
for _ in range(10):
t1 += timeit.timeit(
lambda: func_impl_1(A, rx, ry),
number=1,
)
t2 += timeit.timeit(
lambda: func_impl_2(A, rx, ry),
number=1,
)
m1_ += max(memory_usage(
(lambda: func_impl_1(A, rx, ry),)
))
m2_ += max(memory_usage(
(lambda: func_impl_2(A, rx, ry),)
))
y1.append(t1/100)
y2.append(t2/100)
m1.append(m1_/100)
m2.append(m2_/100)
# Title of first graph:
fig = make_subplots(rows=2, cols=1, shared_xaxes=True, subplot_titles=("Time", "Memory"))
fig.add_trace(go.Scatter(x=x, y=y1, name='func_impl_1 time', legendgroup='1'), row=1, col=1)
fig.add_trace(go.Scatter(x=x, y=y2, name='func_impl_2 time', legendgroup='1'), row=1, col=1)
fig.add_trace(go.Scatter(x=x, y=m1, name='func_impl_1 memory', legendgroup='2'), row=2, col=1)
fig.add_trace(go.Scatter(x=x, y=m2, name='func_impl_2 memory', legendgroup='2'), row=2, col=1)
fig.update_layout(
title="Performance of the functions",
xaxis_title="Matrix size",
)
fig.update_yaxes(title_text="Time (s)", row=1, col=1)
fig.update_yaxes(title_text="Max Memory usage (MB)", row=2, col=1)
fig.show()
图表:
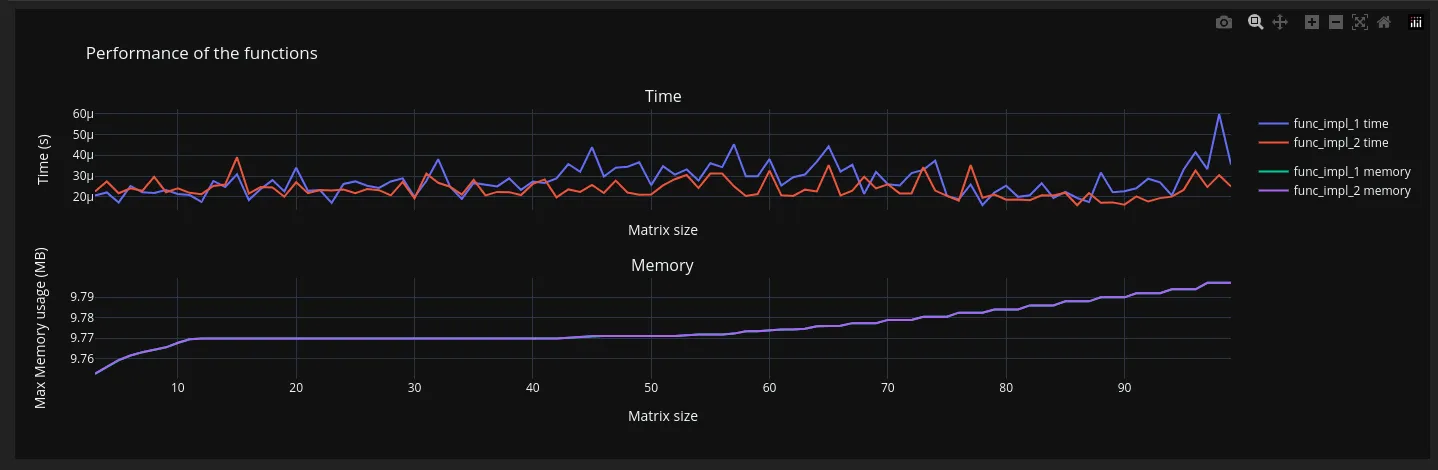
从图表来看,两个函数的内存使用情况相似,这是一个好消息。在运行时间方面,func_impl_2似乎比func_impl_1通常更快,这也是一个积极的发现。然而,两个函数之间的性能差异非常小,并且在非常小的输入大小下,func_impl_1的性能超过了func_impl_2的性能。这可能表明,对于较小的输入,func_impl_1的简单实现仍然是一个可行的选择,即使func_impl_2通常更快。总体而言,这些图表提供了有关这些函数性能的宝贵见解,并可以帮助在不同场景中选择要使用的实现。
%timeit my_code
例如:%timeit a = 1
13.4 ns ± 0.781 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)
基于Danyun Liu的答案,加入了一些便利功能,或许对某些人有用。
def stopwatch(repeat=1, autorun=True):
"""
stopwatch decorator to calculate the total time of a function
"""
import timeit
import functools
def outer_func(func):
@functools.wraps(func)
def time_func(*args, **kwargs):
t1 = timeit.default_timer()
for _ in range(repeat):
r = func(*args, **kwargs)
t2 = timeit.default_timer()
print(f"Function={func.__name__}, Time={t2 - t1}")
return r
if autorun:
try:
time_func()
except TypeError:
raise Exception(f"{time_func.__name__}: autorun only works with no parameters, you may want to use @stopwatch(autorun=False)") from None
return time_func
if callable(repeat):
func = repeat
repeat = 1
return outer_func(func)
return outer_func
def is_in_set(x):
return x in {"linux", "darwin"}
def is_in_list(x):
return x in ["linux", "darwin"]
@stopwatch
def run_once():
import time
time.sleep(0.5)
@stopwatch(autorun=False)
def run_manually():
import time
time.sleep(0.5)
run_manually()
@stopwatch(repeat=10000000)
def repeat_set():
is_in_set("windows")
is_in_set("darwin")
@stopwatch(repeat=10000000)
def repeat_list():
is_in_list("windows")
is_in_list("darwin")
@stopwatch
def should_fail(x):
pass
结果:
Function=run_once, Time=0.5005391679987952
Function=run_manually, Time=0.500624185999186
Function=repeat_set, Time=1.7064883739985817
Function=repeat_list, Time=1.8905151920007484
Traceback (most recent call last):
(some more traceback here...)
Exception: should_fail: autorun only works with no parameters, you may want to use @stopwatch(autorun=False)