我想创建一个数据框,其中包含多列不同长度的数据。由于我认为使用pd.dataframe无法实现这一点,所以我首先创建了一个仅包含零的数据框,现在我想用之前存储的数组(长度不同)替换每一列。我尝试过dataframe.replace和dataframe.update,但是我无法得到想要的结果。
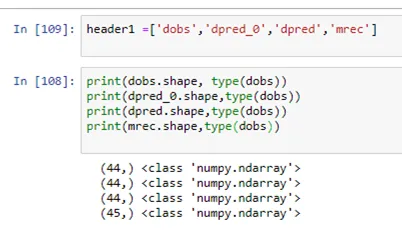
数组的类型和形状为:
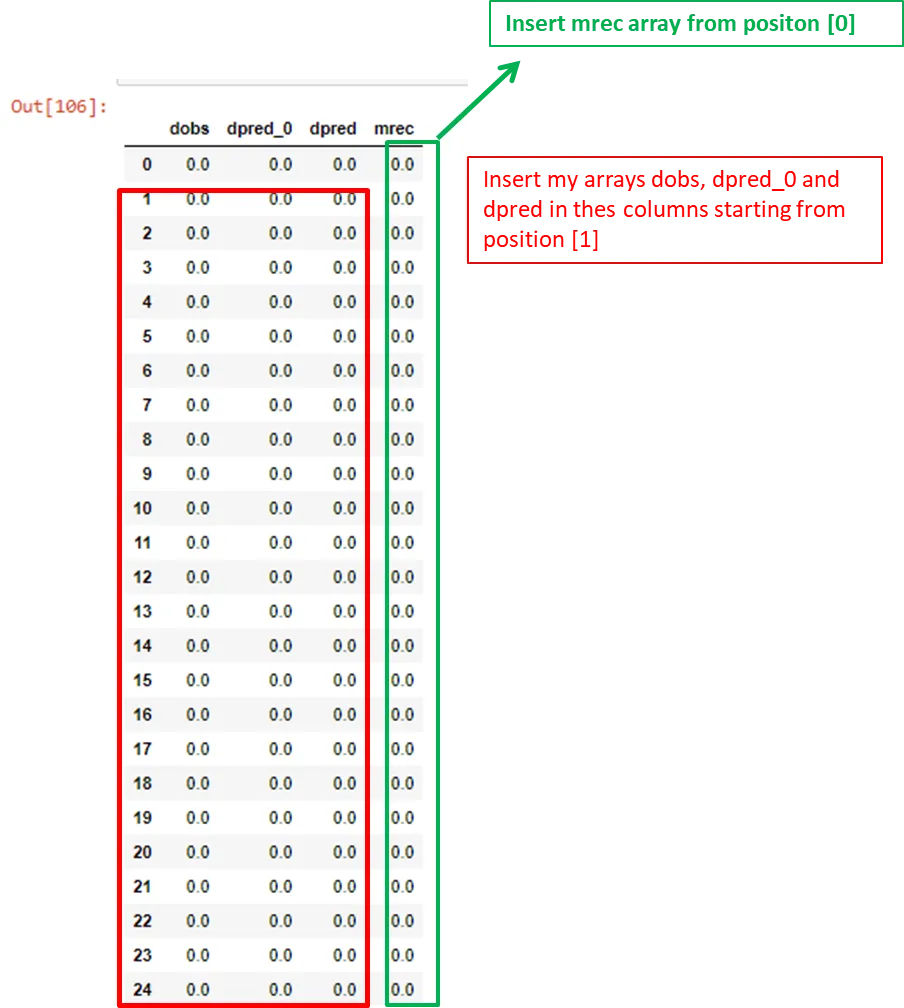
1开始插入数组。你可以这样做:df['dobs'][1:] = dobs
同样对于所有的数组。
考虑一个样例数据框:
df = pd.DataFrame()
df['dobs'] = [0.] * 45
df['dpred_0'] = [0.] * 45
df['dpred'] = [0.] * 45
df['mrec'] = [0.] * 45
dobs = np.array([x for x in range(1, 45)])
dpred_0 = np.array([x for x in range(1, 45)])
dpred = np.array([x for x in range(1, 45)])
mrec = np.array([x for x in range(1, 46)])
Let's check the shapes,
print(dobs.shape, dpred_0.shape, dpred.shape, mrec.shape, df.shape) # ((44,), (44,), (44,), (45,), (45, 4))
如果要替换索引1开始的短数组中的列,可以这样做:
将原始回答替换为:最初的回答
df['dobs'][1:] = dobs
df['dpred_0'][1:] = dpred_0
df['dpred'][1:] = dpred
df['mrec'] = mrec # mrec is of shape (45, ) so no need to start from index 1
dobs dpred_0 dpred mrec
0 0.0 0.0 0.0 1
1 1.0 1.0 1.0 2
2 2.0 2.0 2.0 3
3 3.0 3.0 3.0 4
4 4.0 4.0 4.0 5
random_array = range(0,12)
df['new_column'][0:12] = random_array