首先,bsddb(或其新名称Oracle BerkeleyDB)并未被弃用。
从经验来看,LevelDB / RocksDB / bsddb比
wiredtiger慢,这就是为什么我推荐wiredtiger的原因。
wiredtiger是mongodb的存储引擎,因此在生产中经过了充分的测试。除了我的AjguDB项目外,在Python中几乎没有使用wiredtiger;我使用wiredtiger(通过AjguDB)来存储和查询wikidata和concept,大约80GB。
以下是一个示例类,允许模仿python2
shelve模块。基本上,它是一个wiredtiger后端字典,其中键只能是字符串:
import json
from wiredtiger import wiredtiger_open
WT_NOT_FOUND = -31803
class WTDict:
"""Create a wiredtiger backed dictionary"""
def __init__(self, path, config='create'):
self._cnx = wiredtiger_open(path, config)
self._session = self._cnx.open_session()
self._session.create('table:keyvalue', 'key_format=S,value_format=S')
self._keyvalue = self._session.open_cursor('table:keyvalue')
def __enter__(self):
return self
def close(self):
self._cnx.close()
def __exit__(self, *args, **kwargs):
self.close()
def _loads(self, value):
return json.loads(value)
def _dumps(self, value):
return json.dumps(value)
def __getitem__(self, key):
self._session.begin_transaction()
self._keyvalue.set_key(key)
if self._keyvalue.search() == WT_NOT_FOUND:
raise KeyError()
out = self._loads(self._keyvalue.get_value())
self._session.commit_transaction()
return out
def __setitem__(self, key, value):
self._session.begin_transaction()
self._keyvalue.set_key(key)
self._keyvalue.set_value(self._dumps(value))
self._keyvalue.insert()
self._session.commit_transaction()
这里是来自@saaj答案的适应测试程序:
import os
import random
import lipsum
from wtdict import WTDict
def main():
with WTDict('wt') as wt:
for _ in range(100000):
v = lipsum.generate_paragraphs(2)[0:random.randint(200, 1000)]
wt[os.urandom(10)] = v
if __name__ == '__main__':
main()
使用以下命令行:
python test-wtdict.py & psrecord --plot=plot.png --interval=0.1 $!
我生成了以下图表:
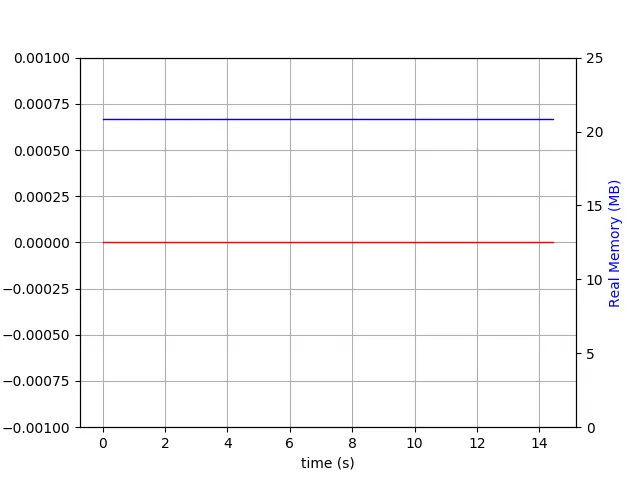
$ du -h wt
60M wt
当写前日志处于活动状态时:
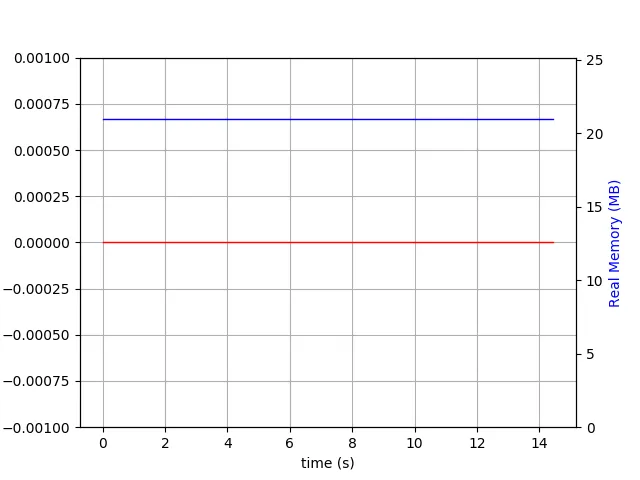
$ du -h wt
260M wt
这是没有进行性能调整和压缩的情况。
WiredTiger 直到最近都没有被发现有任何限制,文档已更新为:
WiredTiger 支持拥有 PB 级别数据表,单条记录大小可达 4GB,记录编号可达 64 位。
http://source.wiredtiger.com/1.6.4/architecture.html
db[key] = value或db.put('key', 'value')那样简单,而是使用SQL语句... 我想避免为了一个简单的键值对db[key] = value的设置/获取而使用INSERT INTO TABLE或SELECT...。 - Basj