我有一些长格式的数据,看起来像这样(请参见下面的重现):
>>> df
section subsection name topic score
0 A W zwphf a 0.802427
1 A W jcyyc a 0.404077
2 A W kucem a 0.367319
3 A X ldbxz a 0.554260
4 A X vkcqh a 0.265864
5 A X cvksn a 0.548099
6 B Y spghx a 0.472612
7 B Y cqokn a 0.577504
8 B Y wjsxg a 0.815309
9 B Z holoo a 0.459850
10 B Z lnihf a 0.667877
11 B Z wirhq a 0.138879
12 A W zwphf b 0.673711
13 A W jcyyc b 0.507962
14 A W kucem b 0.546055
15 A X ldbxz b 0.148214
16 A X vkcqh b 0.773320
17 A X cvksn b 0.791990
18 B Y spghx b 0.487480
19 B Y cqokn b 0.252534
20 B Y wjsxg b 0.237767
21 B Z holoo b 0.432981
22 B Z lnihf b 0.317932
23 B Z wirhq b 0.614401
我想对
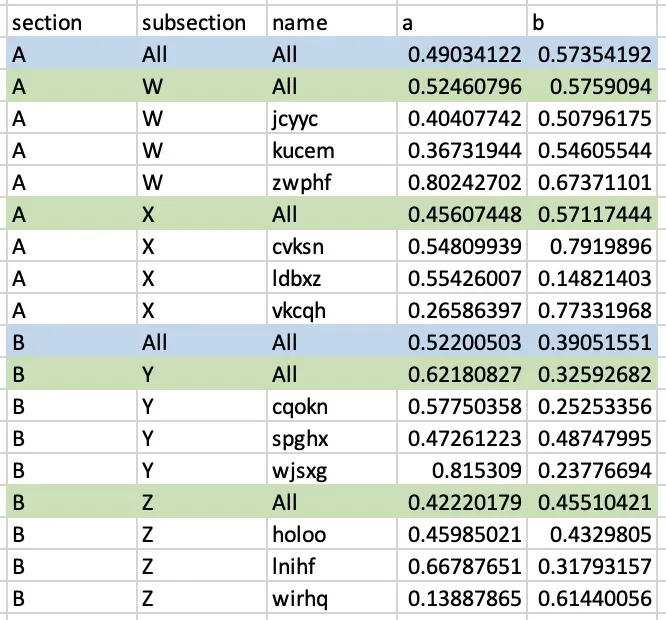
section + subsection + name + topic进行分组,并对topic进行unstack操作,同时显示间歇性嵌套的"All"小计行:>>> result
section subsection name a b
0 A All All 0.490341 0.573542
1 A W All 0.524608 0.575909
2 A W jcyyc 0.404077 0.507962
3 A W kucem 0.367319 0.546055
4 A W zwphf 0.802427 0.673711
5 A X All 0.456074 0.571174
6 A X cvksn 0.548099 0.791990
7 A X ldbxz 0.554260 0.148214
8 A X vkcqh 0.265864 0.773320
9 B All All 0.522005 0.390516
10 B Y All 0.621808 0.325927
11 B Y cqokn 0.577504 0.252534
12 B Y spghx 0.472612 0.487480
13 B Y wjsxg 0.815309 0.237767
14 B Z All 0.422202 0.455104
15 B Z holoo 0.459850 0.432981
16 B Z lnihf 0.667877 0.317932
17 B Z wirhq 0.138879 0.614401
以下内容可能更容易通过新行高亮来可视化:
如果不包含小计,初始的分组结果如下:
>>> df.groupby(['section', 'subsection', 'name', 'topic'])['score'].mean().unstack('topic')
topic a b
section subsection name
A W jcyyc 0.404077 0.507962
kucem 0.367319 0.546055
zwphf 0.802427 0.673711
X cvksn 0.548099 0.791990
ldbxz 0.554260 0.148214
vkcqh 0.265864 0.773320
B Y cqokn 0.577504 0.252534
spghx 0.472612 0.487480
wjsxg 0.815309 0.237767
Z holoo 0.459850 0.432981
lnihf 0.667877 0.317932
wirhq 0.138879 0.614401
但是我不确定如何使用margins来获取基于['section', 'topic']和['section', 'subsection', 'topic']的groupby操作的小计。
要重新创建df:
import pandas as pd
data = [['A', 'W', 'zwphf', 'a', 0.80242702],
['A', 'W', 'jcyyc', 'a', 0.40407741],
['A', 'W', 'kucem', 'a', 0.36731944],
['A', 'X', 'ldbxz', 'a', 0.55426007],
['A', 'X', 'vkcqh', 'a', 0.26586396],
['A', 'X', 'cvksn', 'a', 0.54809939],
['B', 'Y', 'spghx', 'a', 0.47261223],
['B', 'Y', 'cqokn', 'a', 0.57750357],
['B', 'Y', 'wjsxg', 'a', 0.81530899],
['B', 'Z', 'holoo', 'a', 0.45985020],
['B', 'Z', 'lnihf', 'a', 0.66787651],
['B', 'Z', 'wirhq', 'a', 0.13887864],
['A', 'W', 'zwphf', 'b', 0.67371101],
['A', 'W', 'jcyyc', 'b', 0.50796174],
['A', 'W', 'kucem', 'b', 0.54605544],
['A', 'X', 'ldbxz', 'b', 0.14821402],
['A', 'X', 'vkcqh', 'b', 0.77331968],
['A', 'X', 'cvksn', 'b', 0.79198960],
['B', 'Y', 'spghx', 'b', 0.48747995],
['B', 'Y', 'cqokn', 'b', 0.25253355],
['B', 'Y', 'wjsxg', 'b', 0.23776694],
['B', 'Z', 'holoo', 'b', 0.43298050],
['B', 'Z', 'lnihf', 'b', 0.31793156],
['B', 'Z', 'wirhq', 'b', 0.61440056]]
df = pd.DataFrame(data,
columns=['section', 'subsection', 'name', 'topic', 'score'])
重新创建预期结果的方法:
import numpy as np
result = np.array([['A', 'All', 'All', 0.490341219, 0.573541919],
['A', 'W', 'All', 0.52460796, 0.5759094],
['A', 'W', 'jcyyc', 0.404077415, 0.5079617479999999],
['A', 'W', 'kucem', 0.36731944, 0.546055442],
['A', 'W', 'zwphf', 0.8024270240000001, 0.673711011],
['A', 'X', 'All', 0.45607447700000003, 0.571174437],
['A', 'X', 'cvksn', 0.548099391, 0.791989603],
['A', 'X', 'ldbxz', 0.554260074, 0.148214029],
['A', 'X', 'vkcqh', 0.265863967, 0.77331968],
['B', 'All', 'All', 0.5220050279999999, 0.390515513],
['B', 'Y', 'All', 0.621808268, 0.325926816],
['B', 'Y', 'cqokn', 0.577503576, 0.252533557],
['B', 'Y', 'spghx', 0.472612233, 0.487479951],
['B', 'Y', 'wjsxg', 0.815308995, 0.237766941],
['B', 'Z', 'All', 0.42220178799999997, 0.455104209],
['B', 'Z', 'holoo', 0.459850205, 0.43298050200000004],
['B', 'Z', 'lnihf', 0.667876511, 0.317931565],
['B', 'Z', 'wirhq', 0.13887864800000002, 0.61440056]], dtype=object)
result = pd.DataFrame(result, columns=['section', 'subsection', 'name', 'a', 'b'])
.sort_index()假设没有name条目在字典排序时排在单词“'All'”之前。否则,您需要使用其他标记值,然后将其替换。 - Brad Solomons1和s2的.mean()调用将取决于每个组中有相同数量的行这一事实?否则,您需要在['section','subsection','name','topic']上进行完整的分组。 - Brad Solomondf.groupby(level=0).mean()是相同的。 - jezraels进行调用,而不是df,因此这假定每个组中条目的计数具有相等的权重。如果不是这样,您需要再次调用df.mean()而不是s.mean()。无论哪种方式,都是很好的答案。 - Brad Solomon