所以,我正在尝试加载一个csv文件,然后将其保存为parquet文件,最后加载到Hive表中。但是,当我将其加载到表中时,值的位置不正确,且混乱无序。我正在使用Pyspark/Hive。
这是我的csv文件内容: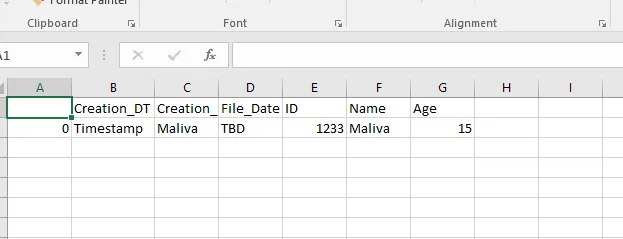 以下是我的代码,用于将csv转换为parquet并将其写入我的HDFS位置:
以下是我的代码,用于将csv转换为parquet并将其写入我的HDFS位置:
这段代码成功将数据转换为parquet格式并存入路径中,但是当我在Hive中使用以下语句进行加载时,输出结果很奇怪。
Hive语句:
这是我的csv文件内容:
以下是我的代码,用于将csv转换为parquet并将其写入我的HDFS位置:#This creates the sparkSession
from pyspark.sql import SparkSession
#from pyspark.sql import SQLContext
spark = (SparkSession \
.builder \
.appName("S_POCC") \
.enableHiveSupport()\
.getOrCreate())
df = spark.read.load('/user/new_file.csv', format="csv", sep=",", inferSchema="true", header="false")
df.write.save('hdfs://my_path/table/test1.parquet')
这段代码成功将数据转换为parquet格式并存入路径中,但是当我在Hive中使用以下语句进行加载时,输出结果很奇怪。
Hive语句:
drop table sndbx_test.test99 purge ;
create external table if not exists test99 ( c0 string, c1 string, c2 string, c3 string, c4 string, c5 string, c6 string);
load data inpath 'hdfs://my_path/table/test1.parquet;
输出:
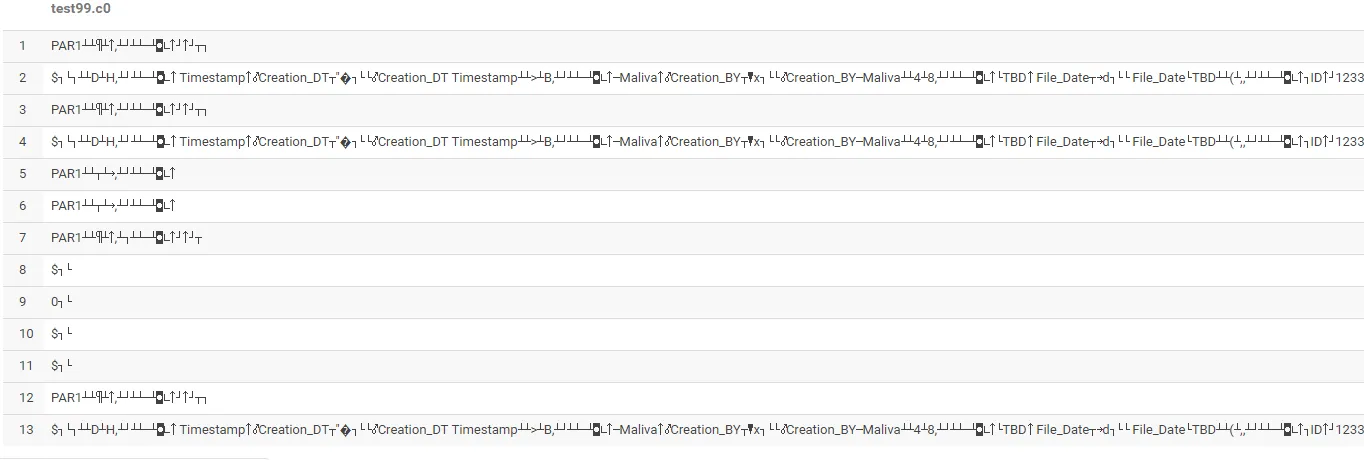
有什么想法/建议吗?