我正在使用Keras为我的项目训练神经网络。Keras提供了早停函数。请问有哪些参数需要注意,以避免在使用早停时过拟合神经网络?
2个回答
191
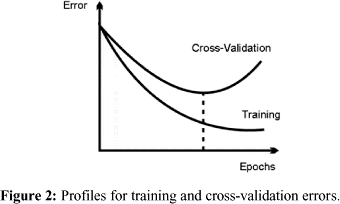
早期停止基本上是指在损失开始增加(或者换句话说验证准确性开始下降)时停止训练。根据文档,它的使用方法如下:
keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=0,
verbose=0, mode='auto')
对于防止过拟合,具体取决于你的实现方式(问题、批处理大小等),但通常会使用以下方法:
- 通过将
monitor参数设置为'val_loss',监控验证集损失(需要使用交叉验证或至少使用训练/测试集)。 min_delta是一个阈值,用于量化某个时期的损失是否有所改善。如果损失的差异小于min_delta,则会被视为未改善。最好将其保留为0,因为我们关心的是损失何时变得更糟。patience参数表示当您的损失开始增加(停止改善)时,在停止之前经过的时期数。这取决于您的实现方式,如果您使用非常小的批次或大学习速率,则损失会发生波动(准确性会更加嘈杂),因此最好设置较大的patience参数。如果您使用大批次和小学习速率,则损失会更平滑,因此可以使用较小的patience参数。无论哪种方式,我都将其设置为2,以便给模型更多机会。verbose决定要打印什么内容,请将其保留为默认值(0)。mode参数取决于您监视数量的方向(它应该是递减还是递增),由于我们监视损失,因此可以使用min。但是让keras为我们处理设置为auto。
因此,我会使用这样的方法,并通过在有和没有早期停止的情况下绘制错误损失来进行实验。
keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=2,
verbose=0, mode='auto')
针对可能存在的回调函数工作机理的歧义,我会尝试做出更详细的解释。一旦您在模型上调用了fit(... callbacks=[es]),Keras就会调用给定回调对象中预定的函数。这些函数可以被调用on_train_begin、on_train_end、on_epoch_begin、on_epoch_end和on_batch_begin、on_batch_end。提前停止回调会在每个 epoch 结束时被调用,将最佳监控值与当前值进行比较,如果满足条件(自最佳监控值观察以来经过了多少个 epoch 和是否超过了耐心参数,上一个值的差异是否大于 min_delta等),则停止训练。
正如@BrentFaust在评论中指出的那样,模型的训练将继续直到提前停止条件被满足或者epochs参数(默认为10)在fit()中得到满足。设置提前停止回调不会使模型超出其epochs参数的训练次数。因此,使用更大的epochs值调用fit()函数将更受益于提前停止回调。
- umutto
13
2
这是另一个项目AutoKeras(https://autokeras.com/)中EarlyStopping的一个例子,该项目是一个自动化机器学习(AutoML)库。该库设置了两个EarlyStopping参数:
patience=10和min_delta=1e-4。
默认监测AutoKeras和Keras的数量是val_loss:
https://github.com/keras-team/keras/blob/cb306b4cc446675271e5b15b4a7197efd3b60c34/keras/callbacks.py#L1748 https://autokeras.com/image_classifier/
- cannin
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
min_delta是一个阈值,用于量化监测值的变化是否为改进。如果我们设置monitor='val_loss',则它将指的是当前验证损失和先前验证损失之间的差异。在实践中,如果您给出min_delta=0.1,那么验证损失的减少(当前值-先前值)小于0.1将不被计算,因此会停止训练(如果您设置了patience=0)。 - umuttocallbacks=[EarlyStopping(patience=2)]只有在将 epochs 参数传递给model.fit(..., epochs=max_epochs)时才会生效。 - Brent Faustepoch=1的fit(用于各种用例),在这种情况下,这个回调函数将失败。如果我的答案有歧义,我会尝试更好地表达它。 - umuttorestore_best_weights参数(尚未在文档中)来加载训练后具有最佳权重的模型。但是,为了您的目的,我建议您使用ModelCheckpoint回调函数和save_best_only参数。您可以查看文档,它很容易使用,但您需要在训练后手动加载最佳权重。 - umutto