我正在学习和尝试神经网络,希望从更有经验的人那里获得以下问题的意见:
当我在Keras中训练一个自编码器(使用'mean_squared_error'损失函数和SGD优化器)时,验证损失逐渐下降,而验证准确率上升。到目前为止都很好。
然而,一段时间后,损失仍在持续下降,但准确率突然回到了一个更低的水平。
- 准确率快速上升并保持高水平然后突然下降是"正常"或者预期行为吗?
- 如果验证损失仍在下降,我应该在达到最大准确率时停止训练吗?换句话说,使用val_acc或val_loss作为监控早期停止的度量标准?
请参见以下图片:
Loss: (绿色 = 验证,蓝色 = 训练]
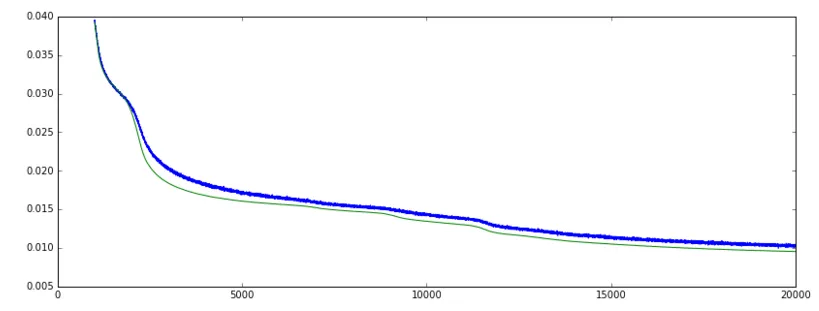
Accuracy: (绿色 = 验证,蓝色 = 训练]

更新: 下面的评论指引我走向正确方向,我现在认为我理解得更好了。如果有人能确认以下内容是否正确,那就太好了:
准确率指标测量y_pred == Y_true的%数,因此仅对分类有意义。
我的数据是实际和二进制特征的组合。准确度图形上升非常迅速,然后再回落,而损失持续降低的原因是,在大约第5000个周期左右,网络可能正确预测了约50%的二进制特征。当训练继续时,在12000个周期左右,实际和二进制特征的预测一起改善,因此损失继续下降,但仅针对二进制特征的预测略微不正确,导致准确性下降,而损失下降。