使用具有DatetimeIndex索引的DataFrame进行外推
这可以通过两个步骤完成:
- 扩展
DatetimeIndex。
- 外推数据。
扩展索引
使用新的
DataFrame 覆盖
df,其中数据基于原始
index's start, period and frequency 的新
扩展 索引进行
resampled。这使得原始的
df 可以来自任何地方,就像
csv 示例案例一样。这样,列会方便地
填充 NaN!
X1 = range(10)
X2 = map(lambda x: x**2, X1)
df = pd.DataFrame({'x1': X1, 'x2': X2}, index=pd.date_range('20130101',periods=10,freq='M'))
extend = 5
df = pd.DataFrame(
data=df,
index=pd.date_range(
start=df.index[0],
periods=len(df.index) + extend,
freq=df.index.freq
)
)
print df
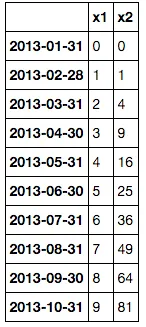
x1 x2
2013-01-31 0 0
2013-02-28 1 1
2013-03-31 2 4
2013-04-30 3 9
2013-05-31 4 16
2013-06-30 5 25
2013-07-31 6 36
2013-08-31 7 49
2013-09-30 8 64
2013-10-31 9 81
2013-11-30 NaN NaN
2013-12-31 NaN NaN
2014-01-31 NaN NaN
2014-02-28 NaN NaN
2014-03-31 NaN NaN
推断数据
大多数推断方法需要输入为数字而非日期。可以通过以下方式实现:
di = df.index
df = df.reset_index().drop('index', 1)
查看此 答案 以了解如何使用 三次多项式 对 DataFrame 的每列值进行外推。
Snippet from answer
for col in fit_df.columns:
x = fit_df.index.astype(float).values
y = fit_df[col].values
params = curve_fit(func, x, y, guess)
col_params[col] = params[0]
for col in df.columns:
x = df[pd.isnull(df[col])].index.astype(float).values
df[col][x] = func(x, *col_params[col])
一旦列被外推,将日期放回。
df.index = di
print df
x1 x2
2013-01-31 0 0
2013-02-28 1 1
2013-03-31 2 4
2013-04-30 3 9
2013-05-31 4 16
2013-06-30 5 25
2013-07-31 6 36
2013-08-31 7 49
2013-09-30 8 64
2013-10-31 9 81
2013-11-30 10 100
2013-12-31 11 121
2014-01-31 12 144
2014-02-28 13 169
2014-03-31 14 196
24替换10有什么问题? - Meldf可以从 .CSV 文件中读取,因此我们无法访问periods参数。 - Nyxynyx