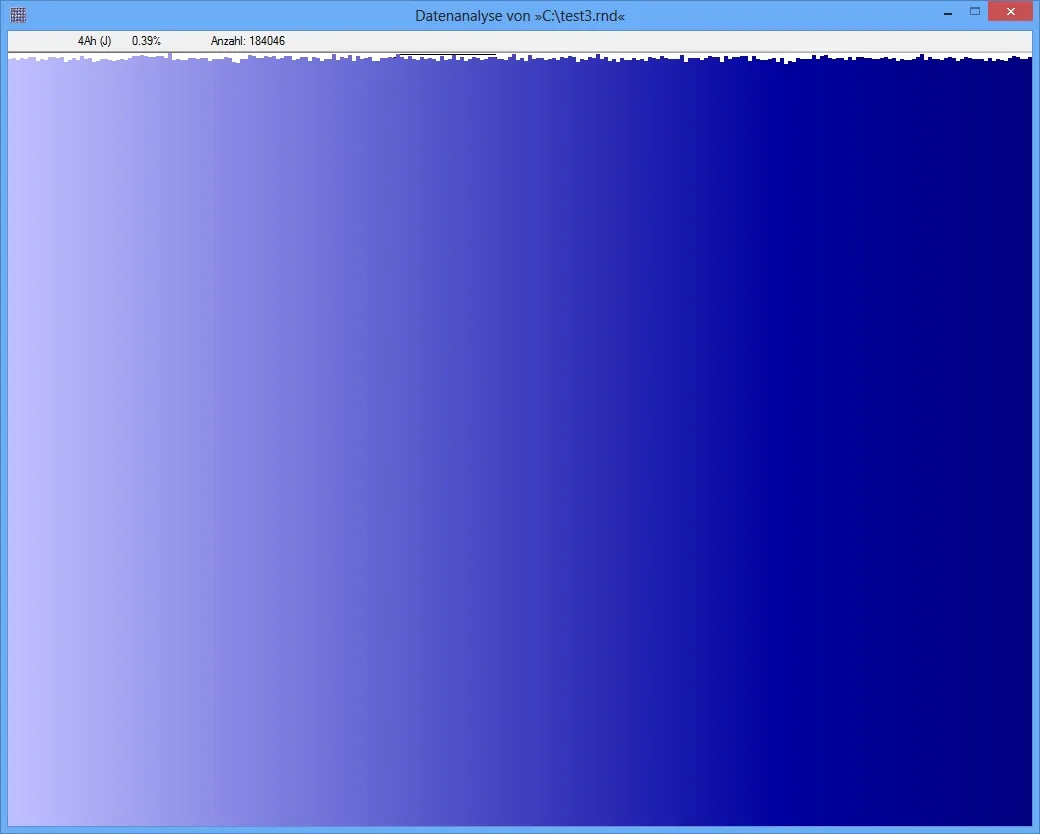
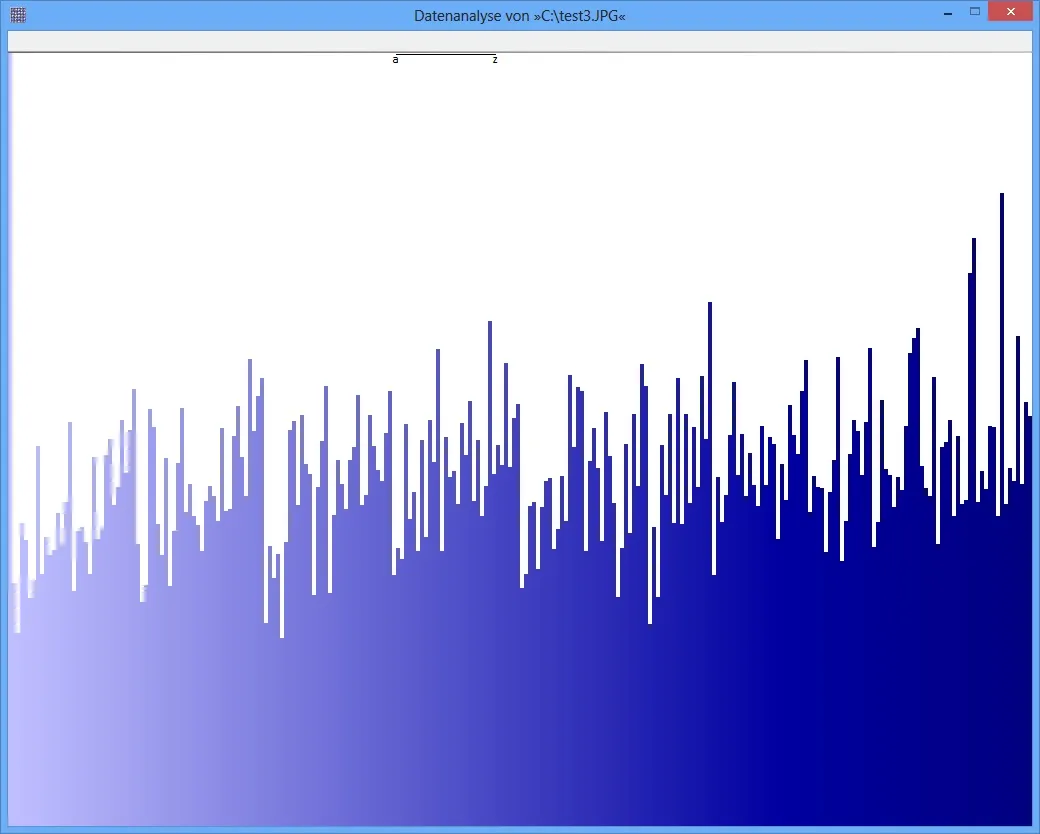
观察压缩数据时,我期望获得几乎均匀分布的字节流。当使用卡方检验来衡量分布时,我会得到这样的结果,例如对于ZIP文件和其他压缩数据,但不适用于JPG文件。最近几天我一直在找出原因,但是我找不到任何原因。
当计算JPG的熵时,我得到了一个高结果(例如7.95比特/字节)。我认为熵和分布之间一定有联系:当每个字节出现的概率几乎相同时,熵就很高。但是当使用卡方检验时,我得到的p值大约为4.5e-5...
我只是想了解不同分布如何影响测试结果...我以为我可以用两种测试方法测量相同的属性,但显然我不能。
非常感谢任何提示! 汤姆
当计算JPG的熵时,我得到了一个高结果(例如7.95比特/字节)。我认为熵和分布之间一定有联系:当每个字节出现的概率几乎相同时,熵就很高。但是当使用卡方检验时,我得到的p值大约为4.5e-5...
我只是想了解不同分布如何影响测试结果...我以为我可以用两种测试方法测量相同的属性,但显然我不能。
非常感谢任何提示! 汤姆