我这里有一个简单的例子,帮助我了解如何使用numba和cython。我对numba和cython都很新。我已经尝试了最好的方法来使numba快速,并且在某种程度上,对于cython也是如此。但是对于float64,我的numpy代码几乎比numba快2倍,如果使用float32,则快2倍以上。不确定我错过了什么。
我想也许问题不再是编码方面,而更多地涉及编译器等,这些我不太熟悉。
我已经浏览了许多有关numpy、numba和cython的stackoverflow帖子,没有直接的答案。
numpy版本:
我想也许问题不再是编码方面,而更多地涉及编译器等,这些我不太熟悉。
我已经浏览了许多有关numpy、numba和cython的stackoverflow帖子,没有直接的答案。
numpy版本:
def py_expsum(x):
return np.sum( np.exp(x) )
Numba版本:
@numba.jit( nopython=True)
def nb_expsum(x):
nx, ny = x.shape
val = 0.0
for ix in range(nx):
for iy in range(ny):
val += np.exp(x[ix, iy])
return val
Cython版本:
import numpy as np
import cython
from libc.math cimport exp
@cython.boundscheck(False)
@cython.wraparound(False)
cpdef double cy_expsum2 ( double[:,:] x, int nx, int ny ):
cdef:
double val = 0.0
int ix, iy
for ix in range(nx):
for iy in range(ny):
val += exp(x[ix, iy])
return val
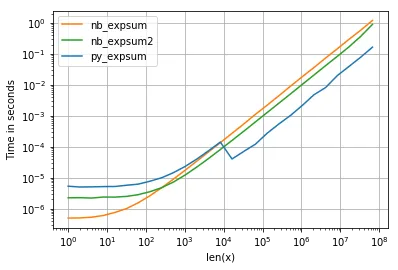
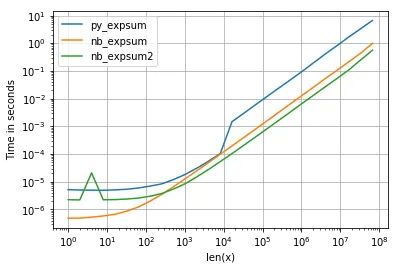
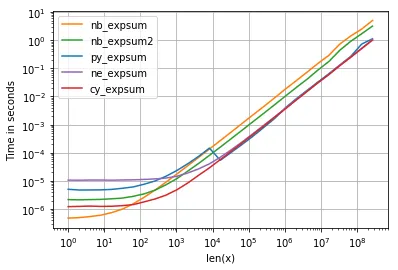
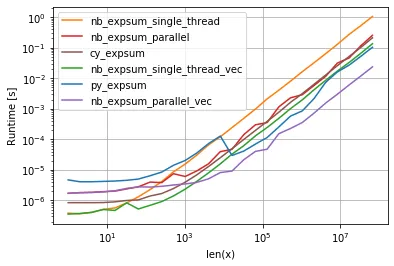
玩弄大小为2000 x 1000的数组,并循环100次。对于numba,第一次启用不计入循环。
使用Python 3(Anaconda发行版),Windows 10。
float64 / float32
1. numpy : 0.56 sec / 0.23 sec
2. numba : 0.93 sec / 0.74 sec
3. cython: 0.83 sec
cython几乎与numba相似。但对我来说,一个大问题是为什么numba跑不过numpy? 我做错了什么或者遗漏了什么?其他因素如何影响性能,我该如何找出原因?
math.exp而不是np.exp。 - Divakarne.evaluate('sum(exp(x))')。 - Brenlla