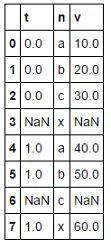
如果在 df 中没有 NaN,则可以创建 MultiIndex,然后使用 reindex,t 中的 NaN 由列 v 设置:
cols = ["n", "t"]
df1 = df.set_index(cols)
mux = pd.MultiIndex.from_product(df1.index.levels, names=cols)
df1 = df1.reindex(mux).sort_index(level=[1,0]).reset_index()
df1['t'] = df1['t'].mask(df1['v'].isnull())
print (df1)
n t v
0 a 0.0 10.0
1 b 0.0 20.0
2 c 0.0 30.0
3 x NaN NaN
4 a 1.0 40.0
5 b 1.0 50.0
6 c NaN NaN
7 x 1.0 60.0
添加 NaN 的另一种解决方案是使用 unstack、stack 方法:
cols = ["n", "t"]
df1 = df.set_index(cols)['v'].unstack().stack(dropna=False)
df1 = df1.sort_index(level=[1,0]).reset_index(name='v')
df1['t'] = df1['t'].mask(df1['v'].isnull())
print (df1)
n t v
0 a 0.0 10.0
1 b 0.0 20.0
2 c 0.0 30.0
3 x NaN NaN
4 a 1.0 40.0
5 b 1.0 50.0
6 c NaN NaN
7 x 1.0 60.0
但是如果一些NaN值需要通过unique的n列值进行groupby和loc:
df = pd.DataFrame({"n": ["a", "b", "c", "a", "b", "x"],
"t": [0, 0, 0, 1, 1, 1],
"v": [10,20,30,40,50,np.nan]})
print (df)
n t v
0 a 0 10.0
1 b 0 20.0
2 c 0 30.0
3 a 1 40.0
4 b 1 50.0
5 x 1 NaN
df1 = df.set_index('n')
.groupby('t', group_keys=False)
.apply(lambda x: x.loc[df.n.unique()])
.reset_index()
print (df1)
n t v
0 a 0.0 10.0
1 b 0.0 20.0
2 c 0.0 30.0
3 x NaN NaN
4 a 1.0 40.0
5 b 1.0 50.0
6 c NaN NaN
7 x 1.0 NaN
df1 = df.groupby('t', group_keys=False)
.apply(lambda x: x.set_index('n').loc[df.n.unique()])
.reset_index()
print (df1)
n t v
0 a 0.0 10.0
1 b 0.0 20.0
2 c 0.0 30.0
3 x NaN NaN
4 a 1.0 40.0
5 b 1.0 50.0
6 c NaN NaN
7 x 1.0 NaN