当我在R中使用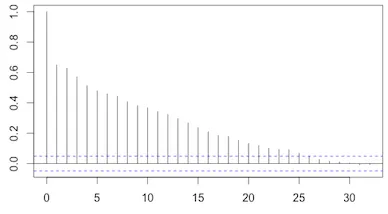 然而,在Python中使用
然而,在Python中使用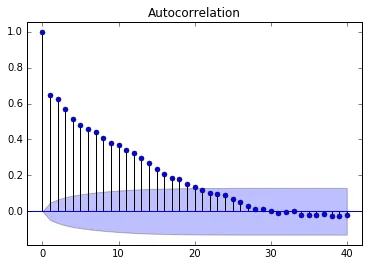 请注意,在R版本中,直到25阶滞后被认为是显著的。对于相同的数据,在Python版本中,只有20阶滞后被认为是显著的。
请注意,在R版本中,直到25阶滞后被认为是显著的。对于相同的数据,在Python版本中,只有20阶滞后被认为是显著的。
这两种方法之间的区别是什么?哪一个应该更可信?有人能解释一下由
我知道可以通过简单地绘制
acf函数时,它会绘制水平线来表示不同滞后下的自相关置信区间(默认为95%):
然而,在Python中使用statsmodels.graphics.tsaplots.plot_acf时,我看到了一个基于更复杂计算的曲线置信区间:
请注意,在R版本中,直到25阶滞后被认为是显著的。对于相同的数据,在Python版本中,只有20阶滞后被认为是显著的。这两种方法之间的区别是什么?哪一个应该更可信?有人能解释一下由
statsmodels.tsa.stattools.acf计算的非常数置信区间的理论吗?我知道可以通过简单地绘制
y=[+/-]1.96 / np.sqrt(len(data))来重现R中的水平线。但是,我想了解这个花哨的曲线置信区间的原理。
statsmodels.graphics.tsaplots.plot_acf函数来绘制常数(白噪声假设)置信区间,方法是包含可选参数bartlett_confint=False,而您可以使用R的acf()函数来绘制非常数(移动平均假设)置信区间,方法是使用参数ci.type='ma'。 - postylem