简单的正则表达式问题。我的字符串格式如下:
this is a [sample] string with [some] special words. [another one]
正则表达式提取方括号内的单词,即:
sample
some
another one
注意:在我的使用情况中,括号不能嵌套。
简单的正则表达式问题。我的字符串格式如下:
this is a [sample] string with [some] special words. [another one]
正则表达式提取方括号内的单词,即:
sample
some
another one
注意:在我的使用情况中,括号不能嵌套。
你可以全局使用以下正则表达式:
\[(.*?)\]
解释:
\[: [ 是元字符,如果你想要匹配它的字面意思,需要转义。(.*?):以非贪婪的方式匹配并捕获所有内容。\]: ] 是元字符,如果你想要匹配它的字面意思,需要转义。(?<=\[).+?(?=\])
将不带括号的内容捕获
(?<=\[) - 正向后瞻,匹配左方括号[
.*? - 匹配非贪婪模式下的内容
(?=\]) - 正向前瞻,匹配右方括号]
编辑:对于嵌套括号,以下正则表达式应该可以解决:
(\[(?:\[??[^\[]*?\]))
. 时,你的嵌套括号解决方案会失败... - patrick[ '[sample]', '[some]', '[another one]' ],而这个答案会返回 [ 'sample', 'some', 'another one' ]。 - iandllnghm这应该可以正常工作:
\[([^]]+)\]
\[([^\[\]]*)\]来获取最内层括号中的内容。如果你查看lfjlksd [ded[ee]22],那么\[([^]]+)\]将会得到[ded[ee],而建议使用的表达式将返回[ee]。在链接中测试过。 - TMC括号可以嵌套吗?
如果不能: \[([^]]+)\] 匹配一个项,包括方括号。反向引用 \1 将包含要匹配的项目。如果你的正则表达式支持环视,请使用。
(?<=\[)[^]]+(?=\])
这只会匹配括号内的项目。
要匹配位于第一个左方括号 [ 和最后一个右方括号 ] 之间的子字符串,您可以使用
\[.*\] # Including open/close brackets
\[(.*)\] # Excluding open/close brackets (using a capturing group)
(?<=\[).*(?=\]) # Excluding open/close brackets (using lookarounds)
查看 正则表达式演示 和 正则表达式演示 #2。
使用以下表达式来匹配字符串在最近的方括号之间:
包括方括号:
\[[^][]*] - PCRE、Python re/regex、.NET、Golang、POSIX(grep、sed、bash)
\[[^\][]*] - ECMAScript(JavaScript、C++ std::regex、VBA RegExp)
\[[^\]\[]*] - Java、ICU regex
\[[^\]\[]*\] - Onigmo(Ruby,需要在所有地方转义括号)
不包括方括号:
(?<=\[)[^][]*(?=]) - PCRE、Python re/regex、.NET(C#等)、JGSoft Software
\[([^\][]*)] - JavaScript、C++ std::regex、VBA RegExp
(?<=\[)[^\]\[]*(?=]) - Java regex、ICU(R stringr)
(?<=\[)[^\]\[]*(?=\]) - Onigmo(Ruby,需要在所有地方转义括号)
注意:*匹配0个或多个字符,请使用+匹配1个或多个字符以避免在结果列表/数组中出现空字符串匹配。
\[((?:[^][]++|(?R))*)] - PHP PCRE\[((?>[^][]+|(?<o>)\[|(?<-o>]))*)] - .NET demo\[(?:[^\]\[]++|(\g<0>))*\] - Onigmo (Ruby) demo\[((?>[^][]+|(?<o>)\[|(?<-o>]))*)]已经满足了我99.9%的需求。我的意思是,我需要最外层括号内的所有内容,但不包括括号本身。例如,在你的.Net演示链接中,它匹配了[text [2]]的所有内容,而我希望匹配返回"text [2]"。然而,我可以通过获取匹配项并执行简单的子字符串来跳过第一个和最后一个字符来解决这个问题。我很好奇是否有可能稍微修改一下这个正则表达式以自动省略最外层的括号。 - B.O.B.如果您不想在匹配中包含方括号,可以使用以下正则表达式:(?<=\[).*?(?=\])
. 匹配除行终止符之外的任何字符。 ?= 是一个正向预查。 正向预查在其后跟随特定字符串时查找字符串。 ?<= 是正向回顾。 正向回顾在其前面有特定字符串时查找字符串。引用这里的话:
正向预查 (?=)
查找 expression B 跟随 expression A 的位置:
A(?=B)正向回顾 (?<=)
查找 expression B 前面的 expression A 的位置:
(?<=B)A
如果您的正则表达式引擎不支持预查和回顾,则可以使用正则表达式 \[(.*?)\]捕获方括号中间的内容,并根据需要操作该组。
括号将字符捕获到一个组中。 .*?以非贪婪的方式获取括号之间的所有字符(除非启用s标志,否则不包括行终止符)。
如果你可能有过不平衡的括号,你可以使用类似递归的表达式进行设计。
\[(([^\]\[]+)|(?R))*+\]
当然,这与您可能正在使用的语言或正则表达式引擎有关。
除此之外,
\[([^\]\[\r\n]*)\]
或者,
(?<=\[)[^\]\[\r\n]*(?=\])
是探索的好选择。
如果您希望简化/修改/探索表达式,则可以在regex101.com的右上面板中进行解释。如果愿意,您还可以在此链接中观看如何对一些示例输入进行匹配。
jex.im用可视化方式展示正则表达式:
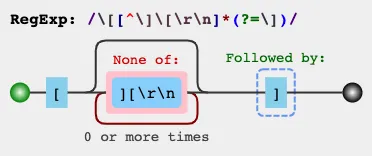
const regex = /\[([^\]\[\r\n]*)\]/gm;
const str = `This is a [sample] string with [some] special words. [another one]
This is a [sample string with [some special words. [another one
This is a [sample[sample]] string with [[some][some]] special words. [[another one]]`;
let m;
while ((m = regex.exec(str)) !== null) {
// This is necessary to avoid infinite loops with zero-width matches
if (m.index === regex.lastIndex) {
regex.lastIndex++;
}
// The result can be accessed through the `m`-variable.
m.forEach((match, groupIndex) => {
console.log(`Found match, group ${groupIndex}: ${match}`);
});
}(?<=\[).*?(?=\]) 根据上面的解释运行良好。以下是Python示例:
import re
str = "Pagination.go('formPagination_bottom',2,'Page',true,'1',null,'2013')"
re.search('(?<=\[).*?(?=\])', str).group()
"'formPagination_bottom',2,'Page',true,'1',null,'2013'"
[])而不是圆括号的。 - Alan Moore这里是@Tim Pietzcker的回答,链接
(?<=\[)[^]]+(?=\])
这几乎是我一直在寻找的答案。但是有一个问题,在一些旧版浏览器中可能无法支持正向后行断言。
所以我必须自己解决:)我设法写出了以下内容:
/([^[]+(?=]))/g
console.log("this is a [sample] string with [some] special words. [another one]".match(/([^[]+(?=]))/g));如果您想在方括号a-z之间仅过滤小写字母
(\[[a-z]*\])
如果您想要使用小写字母和大写字母a-zA-Z
(\[[a-zA-Z]*\])
(\[[a-zA-Z0-9]*\])
如果您想要方括号内的所有内容
如果您想要文字、数字和符号
(\[.*\])
[^]],它比非贪婪(?)更快,并且适用于不支持非贪婪的正则表达式。然而,非贪婪看起来更好看。 - Ipsquiggle[和]符号? - Mickey Tin