我需要一个正则表达式来选择两个外括号之间的所有文本。
例如:
START_TEXT(text here(possible text)text(possible text(more text)))END_TXT
^ ^
结果:
(text here(possible text)text(possible text(more text)))
我需要一个正则表达式来选择两个外括号之间的所有文本。
例如:
START_TEXT(text here(possible text)text(possible text(more text)))END_TXT
^ ^
结果:
(text here(possible text)text(possible text(more text)))
我想添加这个答案以供快速参考。随意更新。
.NET 正则表达式 使用平衡组:
\((?>\((?<c>)|[^()]+|\)(?<-c>))*(?(c)(?!))\)
c 用作深度计数器。
PCRE 使用递归模式:
\((?:[^)(]+|(?R))*+\)
在regex101上的演示;或者没有交替项:
\((?:[^)(]*(?R)?)*+\)
在regex101上的演示; 或者展开以提高性能:
\([^)(]*+(?:(?R)[^)(]*)*+\)
在regex101上的演示;该模式已粘贴在(?R)处,表示(?0)。
Perl、PHP、Notepad++、R:perl=TRUE,Python:PyPI正则表达式模块,使用(?V1)来实现Perl行为。
(PyPI正则表达式包的新版本已经默认使用此方法→ DEFAULT_VERSION = VERSION1)
Ruby 使用 子表达式调用:
在 Ruby 2.0 中,\g<0> 可以用于调用完整的模式。
\((?>[^)(]+|\g<0>)*\)
在 Rubular 上的演示;Ruby 1.9 只支持捕获组递归:
(\((?>[^)(]+|\g<1>)*\))
在Rubular上的演示(自Ruby 1.9.3起的原子分组)
JavaScript API :: XRegExp.matchRecursive
会返回以下内容:XRegExp.matchRecursive(str, '\\(', '\\)', 'g');
Java:@jaytea 的前向引用有趣的想法。
没有递归 最多嵌套3层:
(JS,Java和其他正则表达式风格)
为了防止runaway if unbalanced,只在最内层的[)(]上使用*。
\((?:[^)(]|\((?:[^)(]|\((?:[^)(]|\([^)(]*\))*\))*\))*\)
在regex101上的演示; 或者展开以获得更好的性能(推荐)。
\([^)(]*(?:\([^)(]*(?:\([^)(]*(?:\([^)(]*\)[^)(]*)*\)[^)(]*)*\)[^)(]*)*\)
// JS-Snippet to generate pattern
function generatePattern()
{
// Set max depth & pattern type
let d = document.getElementById("maxDepth").value;
let t = document.getElementById("patternType").value;
// Pattern variants: 0=default, 1=unrolled (more efficient)
let p = [['\\((?:[^)(]|',')*\\)'], ['\\([^)(]*(?:','[^)(]*)*\\)']];
// Generate and display the pattern
console.log(p[t][0].repeat(d) + '\\([^)(]*\\)' + p[t][1].repeat(d));
} generatePattern();Max depth = <input type="text" id="maxDepth" size="1" value="3">
<select id="patternType" onchange="generatePattern()">
<option value="0">default pattern</option>
<option value="1" selected>unrolled pattern</option>
</select>
<input type="submit" onclick="generatePattern()" value="generate!">(?>[^)(]+|(?R))*+与编写(?:[^)(]+|(?R))*+相同。下一个模式也是如此。关于展开版本,您可以在此处放置一个占有量词:[^)(]*+以防止回溯(如果没有关闭括号)。 - Casimir et Hippolyte\{(?>\{(?<c>)|[^{}]+|\}(?<-c>))*(?(c)(?!))\} - MgSam(\((?:[^)(]+|(?1))*+\))(也可以是?2、?3等,取决于分组的编号),而不是 \((?:[^)(]+|(?R))*+\)。?R 总是递归回表达式的开头。如果你只使用这个表达式,那么没问题。但是,例如,如果你在 if 语句后面查找逻辑比较 if \((?:[^)(]+|(?R))*+\) 将无法匹配任何内容,因为需要重复 if 才能匹配括号,而不是仅匹配括号。然而,if (\((?:[^)(]+|(?1))*+\)) 只会检查一次 if,然后递归检查第一个组。 - Trashman无法识别的分组结构。 - nam[^\(]*(\(.*\))[^\)]*
[^\(]* 匹配字符串开头不是左括号的所有内容,(\(.*\)) 捕获被括号包围的子字符串,并且 [^\)]* 匹配字符串末尾不是右括号的所有内容。请注意,此表达式不尝试匹配括号;一个简单的解析器(请参见dehmann's answer)更适合这种情况。
本答案解释了正则表达式为什么不是处理此任务的正确工具的理论限制。
正则表达式无法实现此功能。
正则表达式基于一种称为有限状态自动机(FSA)的计算模型。正如名称所示,FSA只能记住当前状态,它没有关于以前状态的信息。
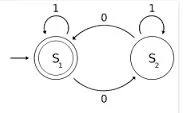
在上图中,S1和S2是两个状态,其中S1是起始和最终步骤。因此,如果我们尝试使用字符串0110,转换如下:
0 1 1 0
-> S1 -> S2 -> S2 -> S2 ->S1
S2 时,即解析完 0110 中的 01 后,有限状态自动机对于 01 中前面的 0 没有任何信息,因为它只能记住当前状态和下一个输入符号。(?<=\().*(?=\))
如果你想选择两个匹配括号之间的文本,那么使用正则表达式将无法实现(*)。
这个正则表达式只会返回你字符串中第一个左括号和最后一个右括号之间的文本。
(*) 除非你的正则表达式引擎具有像平衡组或递归这样的特性。支持这些功能的引擎数量正在缓慢增长,但它们仍然不是常见的。
当处理嵌套模式时,我也曾陷入困境,而正则表达式是解决这类问题的正确工具。
/(\((?>[^()]+|(?1))*\))/
这是正则表达式的终极版:
\(
(?<arguments>
(
([^\(\)']*) |
(\([^\(\)']*\)) |
'(.*?)'
)*
)
\)
例子:
input: ( arg1, arg2, arg3, (arg4), '(pip' )
output: arg1, arg2, arg3, (arg4), '(pip'
'(pip' 被正确地处理为字符串。
(在正则表达式测试工具中尝试:http://sourceforge.net/projects/regulator/)除了bobble bubble的答案,还有其他支持递归结构的正则表达式风格。
Lua
使用%b()(花括号/方括号使用%b{}/%b[]):
for s in string.gmatch("Extract (a(b)c) and ((d)f(g))", "%b()") do print(s) end(请参见演示)Raku(前Perl6):
非重叠多个平衡括号匹配:
my regex paren_any { '(' ~ ')' [ <-[()]>+ || <&paren_any> ]* }
say "Extract (a(b)c) and ((d)f(g))" ~~ m:g/<&paren_any>/;
# => (「(a(b)c)」 「((d)f(g))」)
重叠的多个平衡括号匹配:
say "Extract (a(b)c) and ((d)f(g))" ~~ m:ov:g/<&paren_any>/;
# => (「(a(b)c)」 「(b)」 「((d)f(g))」 「(d)」 「(g)」)
请查看演示。
Python re 非正则解决方案
请查看poke的答案以获取如何在平衡的括号之间获取表达式。
Java 可定制的非正则解决方案
这是一个允许单个字符文字分隔符的可定制解决方案,适用于Java:
public static List<String> getBalancedSubstrings(String s, Character markStart,
Character markEnd, Boolean includeMarkers)
{
List<String> subTreeList = new ArrayList<String>();
int level = 0;
int lastOpenDelimiter = -1;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == markStart) {
level++;
if (level == 1) {
lastOpenDelimiter = (includeMarkers ? i : i + 1);
}
}
else if (c == markEnd) {
if (level == 1) {
subTreeList.add(s.substring(lastOpenDelimiter, (includeMarkers ? i + 1 : i)));
}
if (level > 0) level--;
}
}
return subTreeList;
}
}
示例用法:
String s = "some text(text here(possible text)text(possible text(more text)))end text";
List<String> balanced = getBalancedSubstrings(s, '(', ')', true);
System.out.println("Balanced substrings:\n" + balanced);
// => [(text here(possible text)text(possible text(more text)))]