动机
许多数据集足够大,以至于我们需要考虑速度/效率。因此,我提供了这个解决方案来迎合这一需求。它碰巧也很简洁。
为了比较起见,让我们删除index列。
df = data_set.drop('index', 1)
解决方案
我建议使用zip和map
list(zip(*map(df.get, df)))
[('2012-02-17', 24.75, 25.03),
('2012-02-16', 25.0, 25.07),
('2012-02-15', 24.99, 25.15),
('2012-02-14', 24.68, 25.05),
('2012-02-13', 24.62, 24.77),
('2012-02-10', 24.38, 24.61)]
如果我们想处理特定的列子集,它也很灵活。我们假设我们已经显示的列是我们想要的子集。
list(zip(*map(df.get, ['data_date', 'data_1', 'data_2'])))
[('2012-02-17', 24.75, 25.03),
('2012-02-16', 25.0, 25.07),
('2012-02-15', 24.99, 25.15),
('2012-02-14', 24.68, 25.05),
('2012-02-13', 24.62, 24.77),
('2012-02-10', 24.38, 24.61)]
什么是 Quicker?
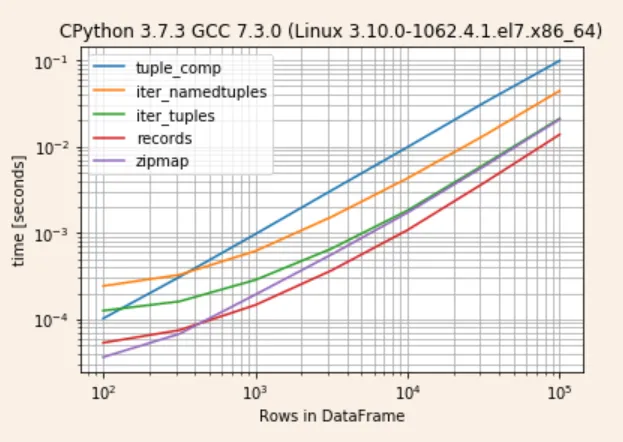
事实证明,在渐近收敛的情况下,records 是最快的,其次是 zipmap 和 iter_tuples
我将使用一个库simple_benchmarks,该库来源于这篇文章
from simple_benchmark import BenchmarkBuilder
b = BenchmarkBuilder()
import pandas as pd
import numpy as np
def tuple_comp(df): return [tuple(x) for x in df.to_numpy()]
def iter_namedtuples(df): return list(df.itertuples(index=False))
def iter_tuples(df): return list(df.itertuples(index=False, name=None))
def records(df): return df.to_records(index=False).tolist()
def zipmap(df): return list(zip(*map(df.get, df)))
funcs = [tuple_comp, iter_namedtuples, iter_tuples, records, zipmap]
for func in funcs:
b.add_function()(func)
def creator(n):
return pd.DataFrame({"A": random.randint(n, size=n), "B": random.randint(n, size=n)})
@b.add_arguments('Rows in DataFrame')
def argument_provider():
for n in (10 ** (np.arange(4, 11) / 2)).astype(int):
yield n, creator(n)
r = b.run()
检查结果
r.to_pandas_dataframe().pipe(lambda d: d.div(d.min(1), 0))
tuple_comp iter_namedtuples iter_tuples records zipmap
100 2.905662 6.626308 3.450741 1.469471 1.000000
316 4.612692 4.814433 2.375874 1.096352 1.000000
1000 6.513121 4.106426 1.958293 1.000000 1.316303
3162 8.446138 4.082161 1.808339 1.000000 1.533605
10000 8.424483 3.621461 1.651831 1.000000 1.558592
31622 7.813803 3.386592 1.586483 1.000000 1.515478
100000 7.050572 3.162426 1.499977 1.000000 1.480131
r.plot()
list(df.itertuples(index=False, name=None))。 - Ted Petroudf.to_records(index=False)和字典列表 -df.to_dict('records')。 - Martin Thoma