我将设置以下示例,它类似于我的情况和数据:
假设我有以下DataFrame:
现在,我有以下函数,根据以下逻辑返回折扣金额:
现在我想要的结果DataFrame是:
假设我有以下DataFrame:
df = pd.DataFrame ({'ID' : [1,2,3,4],
'price' : [25,30,34,40],
'Category' : ['small', 'medium','medium','small']})
Category ID price
0 small 1 25
1 medium 2 30
2 medium 3 34
3 small 4 40
现在,我有以下函数,根据以下逻辑返回折扣金额:
def mapper(price, category):
if category == 'small':
discount = 0.1 * price
else:
discount = 0.2 * price
return discount
现在我想要的结果DataFrame是:
Category ID price Discount
0 small 1 25 0.25
1 medium 2 30 0.6
2 medium 3 40 0.8
3 small 4 40 0.4
所以我决定在价格列上调用series.map,因为我不想使用apply。我正在处理一个大型的DataFrame,而map比apply更快。
我尝试过这样做:
for c in list(sample.Category.unique()):
sample[sample['Category'] == c]['Discount'] = sample[sample['Category'] == c]['price'].map(lambda x: mapper(x,c))
我的期望没有实现,因为我试图在 DataFrame 的切片副本上设置一个值。
我的问题是,
有没有一种方法可以不使用 df.apply() 来实现这个?
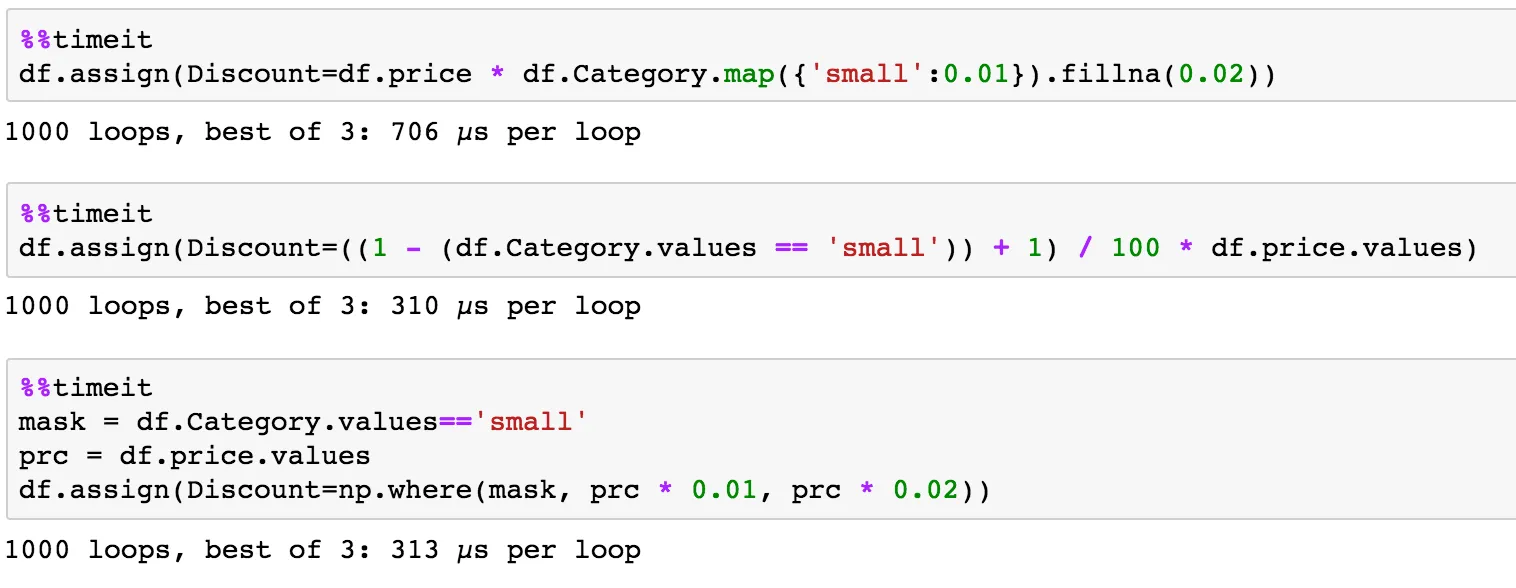
df.assign比df['column_name'] =更高效吗? - Divakarpd.DataFrame.assign的便利之处在于它会生成一个副本,其中包含关键字参数指定的新列。这对于基准测试很有用,因为它不会覆盖原始数据。对于流水线操作也非常实用。我在你的示例中使用它,以便我们可以进行苹果与苹果的比较,而无需在每次迭代中重新创建df。 - piRSquared