我正在对DataFrame进行过滤,以获得曲线下的面积。我已经成功地得到了曲线的边界,因此我们只想要该曲线下的行。
我采用的方法是通过以下代码中的代码(1)获取 data_y_border(图中的红色曲线) (这个方法很有效)。这将包含另一列值>= 0.7的每个X的最顶部Y,以便我可以查询data_y_border[x_value]并获取相应的最顶部Y。
注意: data_y_border不是整个数据集中Y的最低值。 data(图中的蓝色矩形)是我们的数据集,而data_y_border是由Density列定义的红色区域的下边界,其中其值大于0.7:
density_zone = data[
(full_dataset["X" < x_right_boundary)
& (full_dataset['Density'] >= 0.7)
& (full_dataset['Y'] > y_lower_boundary)
]
data_y_border 是红色区域的底部。它下面的任何内容都没有密度大于0.7。
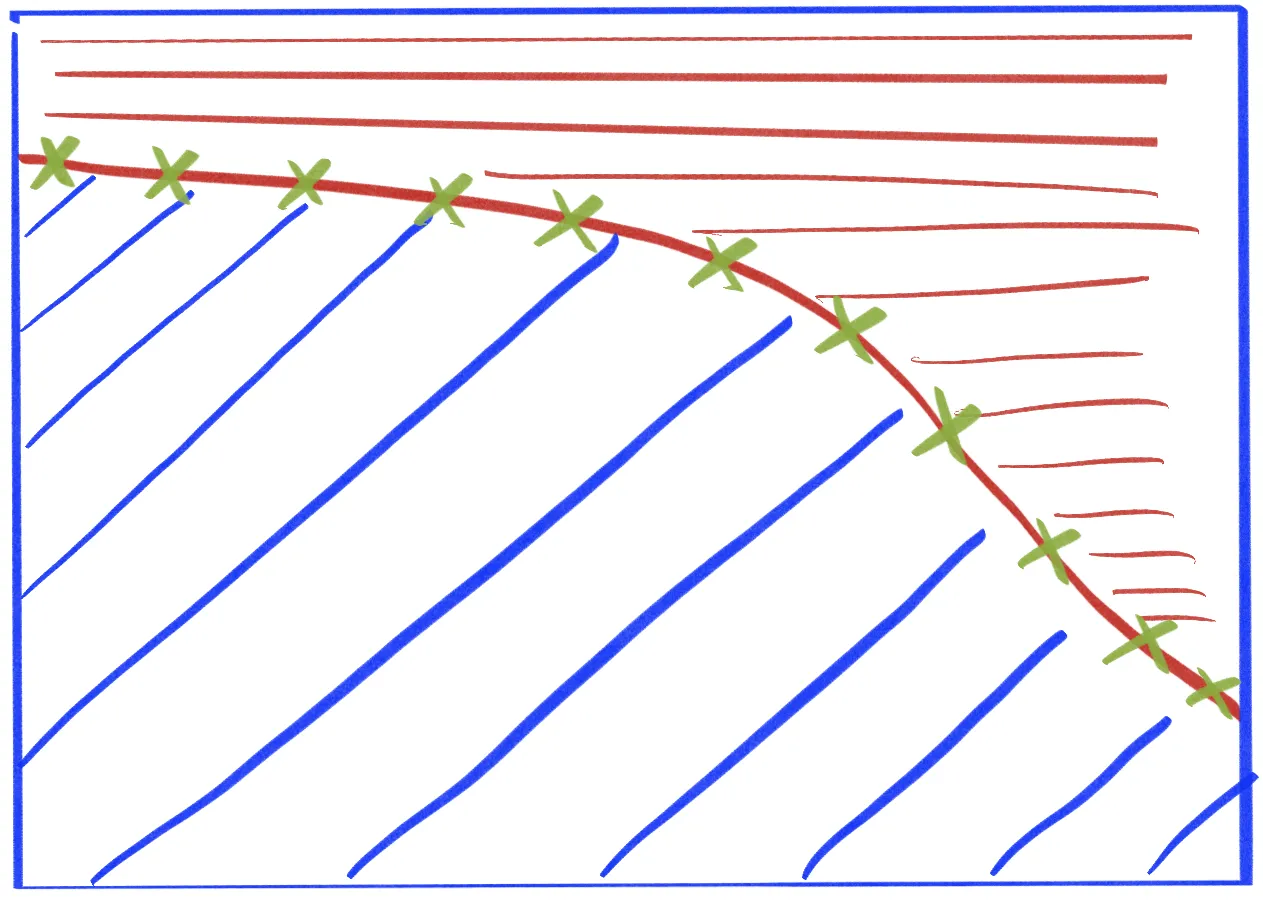
我现在想使用每个 X 位置的 Y 值,保留所有行,其中该 X 值对应的 Y ≤ 最顶部 Y 的值(在 data_y_border 中)。
我正在尝试使用 [2] 中的 loc 和 lambda 的组合来将行值与每行的最顶部 Y 进行比较,但我收到错误信息:
ValueError: Can only compare identically-labeled Series objects
代码:
[1] data_y_border = density_zone.groupby("X")["Y"].min() #returns Series
or
data_y_border = density_zone.loc[density_zone.groupby("X")["Y"].idxmin() # returns DataFrame
# as per @enke's suggestion
[2] data.loc[lambda row: row['Y'] <= data_y_border.get(row['X'])]
# get the X value for `row`,
# use it as the index in `data_y_border` to get the corresponding Y // value,
# compare that row's Y value to see if it's less than or equal to the topmost Y.
# If it is, keep it
数据框中大约有23个列,但作为示例,给定以下
数据数据框和data_y_border,我期望保留下面的预期输出:data =
X Y OtherDataIWantToKeep
2.0 307.0 ...
2.0 155.3 ...
2.0 120.0 ...
2.0 80.2 ...
4.0 500.3 ...
4.0 270.8 ...
4.0 111.2 ...
4.0 78.23 ...
4.0 6.3 ...
data_y_border=
2.0, 155.3
4.0, 111.2
预期输出行数(包括其他列中的所有数据):
X Y OtherDataIWantToKeep
2.0 155.3 ...
2.0 120.0 ...
2.0 80.2 ...
4.0 111.2 ...
4.0 78.23 ...
4.0 6.3 ...
我尝试了涉及.apply的组合,但是这种方法会导致键错误。我感觉问题出在上面代码中的data_y_border.get(row ['X'])部分,Pandas不喜欢在单独的筛选器上运行查询以使用该值来过滤当前数据帧。
使用loc和lambda过滤每个行的数据帧并将每行的值与另一个数据帧/系列中的映射值进行比较是否正确?
我考虑过iterrows(如果它们是Python / JS中的数组/列表,我会对它们进行映射),但这对于相当大的数据帧来说太昂贵了。
data_y_border不能是data.groupby("X")["Y"].min()的输出。例如,对于2.0,120.0<155.3。实际上,data_y_border是如何推导出来的? - user7864386