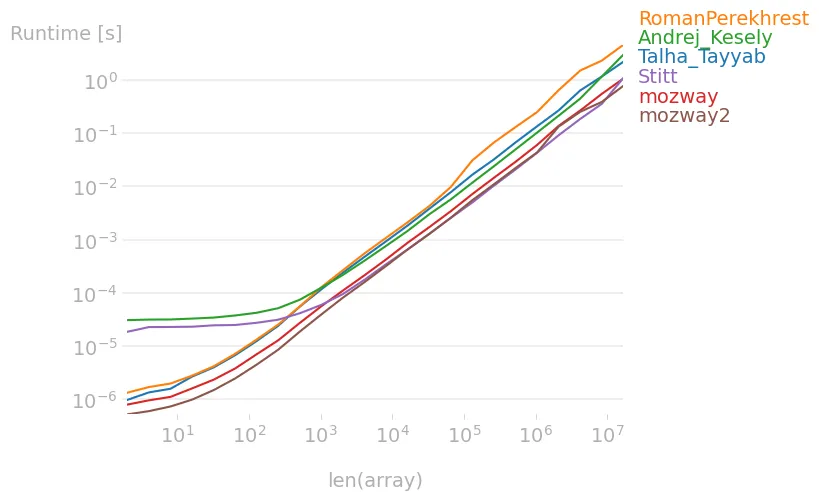
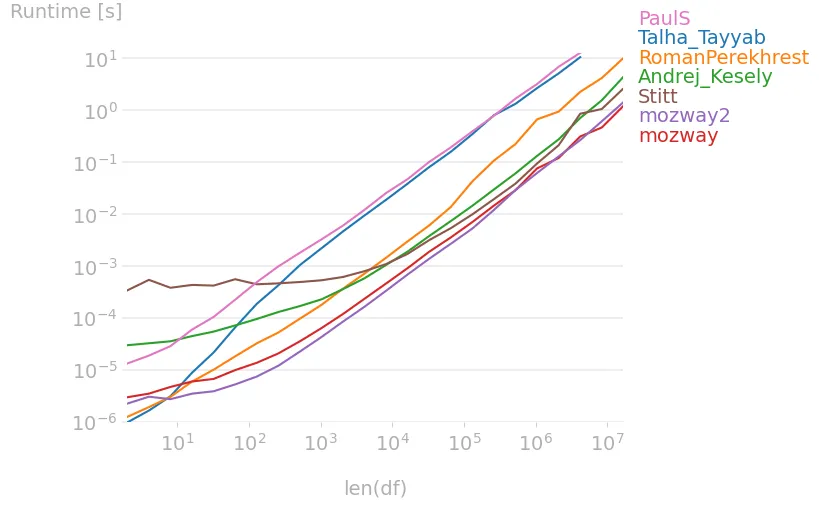
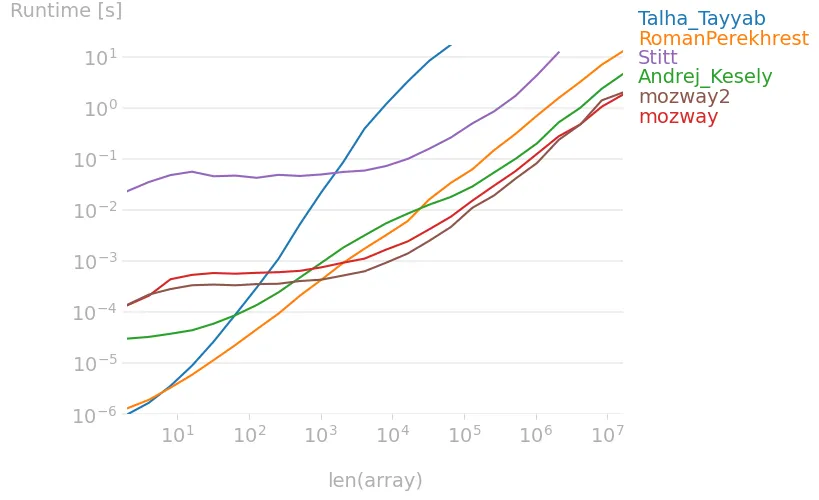
给定以下数组:
我需要找到相同数字出现的索引。 在这个例子中,它会返回一个类似这样的列表的列表:
array = [-1, -1, -1, -1, -1, -1, 3, 3, -1, 3, -1, -1, 2, 2, -1, -1, 1, -1]
indexes 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
我需要找到相同数字出现的索引。 在这个例子中,它会返回一个类似这样的列表的列表:
list(list(), list(16), list(12, 13), list(6, 7, 9), list() etc...)
0 1 \ 2 3 4
^ \
\ \ the index in the array at which "1" appears
\
\ the numbers in the array
numpy 中该如何实现?
数字 1 出现在索引 16 处
数字 2 出现在索引 12、13 处
等等。
基于评论的注意事项:
-1 可以忽略,我只对其他值感兴趣
数组有大约50个元素,取值范围为 int(500)
此函数将被调用6000多次。