我对Pandas的理解比较薄弱,对Python也不是很熟悉。
我想要根据现有列(d.Company和d2.Alias)的值来更新一个列(d.Alias)。如果d2.Alias是d.Company的子字符串,则d.Alias应该等于d2.Alias。
数据集示例:
d = {'Company': ['The Cool Company Inc', 'Cool Company, Inc', 'The Cool
Company', 'The Shoe Company', 'Muffler Store', 'Muffler Store'],
'Position': ['Cool Job A', 'Cool Job B', 'Cool Job C', 'Salesman',
'Sales', 'Technician'],
'City': ['Tacoma', 'Tacoma','Tacoma', 'Boulder', 'Chicago', 'Chicago'],
'State': ['AZ', 'AZ', 'AZ', 'CO', 'IL', 'IL'],
'Alias': [np.nan, np.nan, np.nan, np.nan, np.nan, np.nan]}
d2 = {'Company': ['The Cool Company, Inc.', 'The Shoe Company', 'Muffler
Store LLC'],
'Alias': ['Cool Company', np.nan, 'Muffler'],
'First Name': ['Carol', 'James', 'Frankie'],
'Last Name': ['Fisher', 'Smith', 'Johnson']}
np.nan 对于 The Shoe Company 来说不需要使用别名。我尝试过使用 .loc、for 循环、while 循环、pandas.where、numpy.where 等多种方法,但都没有得到期望的结果。在使用 for 循环时,d2.Alias 的末尾被复制到了 d.Alias 的所有行中。然而,我无法重现这个结果。我查看了之前的帖子,但是要么无法让它们工作,要么我无法理解它们:Conditionally fill column with value from another DataFrame based on row match in Pandas pandas create new column based on values from other columns。
非常感谢任何帮助!
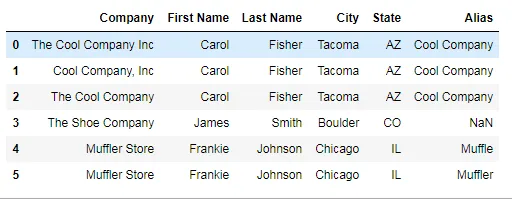
编辑: 期望输出:Expected output 更新: 调整几天后,我达到了所需的结果。根据 Wen 的回答,我必须更改一些东西。首先,我从
{kind=link}
df2.Alias 创建了一个名为 aliases 的列表:aliases = df2.Alias.unique()。然后,我需要删除 .map(df2.set_index('Company').Alias。生成我的所需结果的代码行:df1['Alias'] = df1.Company.apply(lambda x: [process.extract(x, aliases, limit=1)][0][0][0])。
d2.Alias包含在d.Company中”是什么意思。 - harvpan