在MS SQL Server(我使用的是2005版本)中,当您在一个或多个列上创建索引时,您可以指定每个列上的索引是升序还是降序。我不太明白为什么要做这个选择。使用二进制排序技术,无论哪种方式进行查找速度都应该是一样快的,那么我选择哪个顺序有什么区别呢?
3个回答
162
这主要与复合索引一起使用时有关:
CREATE INDEX ix_index ON mytable (col1, col2 DESC);
可以用于以下任一情况:
SELECT *
FROM mytable
ORDER BY
col1, col2 DESC
或者:
SELECT *
FROM mytable
ORDER BY
col1 DESC, col2
但不适用于:
SELECT *
FROM mytable
ORDER BY
col1, col2
单列索引可用于双向排序,且可高效使用。
有关详细信息,请参见我的博客文章:
更新:
实际上,即使是单列索引,这也可能很重要,尽管不太明显。
想象一下对群集表中的某个列创建的索引:
CREATE TABLE mytable (
pk INT NOT NULL PRIMARY KEY,
col1 INT NOT NULL
)
CREATE INDEX ix_mytable_col1 ON mytable (col1)
col1上的索引维护了按顺序排列的col1值以及行的引用。
由于该表是聚集索引,行的引用实际上是pk的值。它们在每个col1值内也是有序的。
这意味着索引的叶子节点实际上是按照(col1, pk)排序的,并且此查询:
SELECT col1, pk
FROM mytable
ORDER BY
col1, pk
无需排序。
如果我们按照以下方式创建索引:
CREATE INDEX ix_mytable_col1_desc ON mytable (col1 DESC)
如果使用该语句,col1 的值将按降序排序,但在每个 col1 值中,pk 的值将按升序排序。
这意味着以下查询:
SELECT col1, pk
FROM mytable
ORDER BY
col1, pk DESC
可以使用ix_mytable_col1_desc进行服务,但无法使用ix_mytable_col1。
换句话说,在任何表上构成聚集索引的列始终是该表上任何其他索引的尾随列。
- Quassnoi
4
82
就查询优化器而言,对于真正的单列索引,这并没有太大区别。
至于表格定义
CREATE TABLE T1( [ID] [int] IDENTITY NOT NULL,
[Filler] [char](8000) NULL,
PRIMARY KEY CLUSTERED ([ID] ASC))
查询
SELECT TOP 10 *
FROM T1
ORDER BY ID DESC
使用有序扫描并设置扫描方向为BACKWARD,如执行计划所示。但是目前只能并行进行FORWARD扫描。
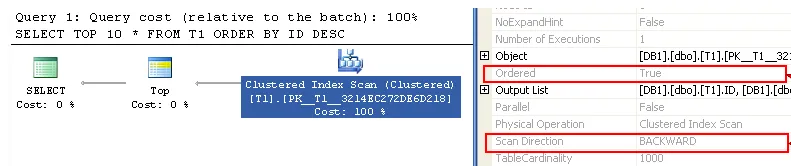
然而在逻辑分散方面,它可能会产生很大的影响。如果索引是按降序创建的,但是新行以升序键值附加,则每个页都可能无序。这可能会严重影响扫描表时的IO读取大小,并且未被缓存。
请参见分散结果。
avg_fragmentation avg_fragment
name page_count _in_percent fragment_count _size_in_pages
------ ------------ ------------------- ---------------- ---------------
T1 1000 0.4 5 200
T2 1000 99.9 1000 1
对于下面的脚本:
/*Uses T1 definition from above*/
SET NOCOUNT ON;
CREATE TABLE T2( [ID] [int] IDENTITY NOT NULL,
[Filler] [char](8000) NULL,
PRIMARY KEY CLUSTERED ([ID] DESC))
BEGIN TRAN
GO
INSERT INTO T1 DEFAULT VALUES
GO 1000
INSERT INTO T2 DEFAULT VALUES
GO 1000
COMMIT
SELECT object_name(object_id) AS name,
page_count,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages
FROM
sys.dm_db_index_physical_stats(db_id(), object_id('T1'), 1, NULL, 'DETAILED')
WHERE index_level = 0
UNION ALL
SELECT object_name(object_id) AS name,
page_count,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages
FROM
sys.dm_db_index_physical_stats(db_id(), object_id('T2'), 1, NULL, 'DETAILED')
WHERE index_level = 0
可以使用"空间结果"选项卡来验证这一假设,即两种情况下后面的页面键值都是递增的。
SELECT page_id,
[ID],
geometry::Point(page_id, [ID], 0).STBuffer(4)
FROM T1
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
UNION ALL
SELECT page_id,
[ID],
geometry::Point(page_id, [ID], 0).STBuffer(4)
FROM T2
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )

- Martin Smith
7
谢谢Martin提供这个好的技巧,这确实帮助我在排名查询方面。 - TheGameiswar
我想知道如果我有一个降序索引,那么当 @myvalue 接近最大可能值时,从 mytable 中选择 indexed_column = @myvalue 的 mycolumn 是否比接近最小可能值时更快。 - Lajos Arpad
@LajosArpad 为什么一个会更快?B树是平衡树。树的深度对于两者都是相同的。 - Martin Smith
@MartinSmith,如果兄弟节点的顺序稍有不同就会影响性能,那么运行数百万次选择操作将会累加,更不用说多维连接了。 - Lajos Arpad
@MartinSmith,让我们考虑一下选择具有正向索引和反向索引增量之间的区别。基本上,如果增量不完全为0,它可能是非常小的负数或非常小的正数,那么将其乘以足够大的数字,您就会得到一个可测量的差异。 - Lajos Arpad
显示剩余2条评论
9
当您想检索大量排序数据而不是单个记录时,排序顺序很重要。
请注意(正如您在问题中提出的那样),排序顺序通常比索引哪些列更重要(如果顺序与所需相反,则系统可以反向读取索引)。我很少考虑索引排序顺序,而是纠结于索引覆盖的列。
@Quassnoi提供了一个很好的例子,说明它确实很重要。
- Michael Haren
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
DESC可以加速顺序数据的碎片化。 您可以按任何方式排序,无需为每个可能性创建新索引。 当然,您可能会在排序上节省几毫秒,但用户是否能感知到呢? 这是否值得所有仅用于排序的新索引所需的额外磁盘空间和IO? 这是否值得您为每个插入/更新/删除添加的开销? 这是否值得更大、更慢的备份?备份始终包括索引! 我的经验法则是: 对于所有常见过滤器,请使用1列索引,并仅为常见分组过滤器和复合FK添加多列索引。 - MikeTeeVee