是的,原始递归解决方法需要很长时间。这是因为对于每个计算的数字,它都需要多次计算之前的所有数字。看一下以下图片。
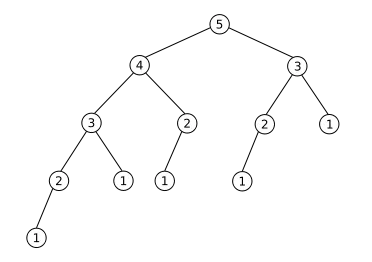
它表示使用您的函数计算Fibonacci(5)。正如您所看到的,它计算了Fibonacci(2)的值三次,以及Fibonacci(1)的值五次。随着您要计算的数字越来越高,这种情况只会变得更糟。
让它变得更加糟糕的是,在计算列表中的每个斐波那契数时,您不使用已经知道的先前数字来加速计算-每个数字都是“从头开始”计算的。
有几种方式可以使此过程更快:
1. 从下到上创建列表
最简单的方法就是创建一个斐波那契数列表,直到您想要的数字为止。如果这样做,您就可以“从下到上”或者说另一种说法是“自底向上”构建,可以重复使用先前的数字来创建下一个数字。如果您有一个斐波那契数列表[0, 1, 1, 2, 3],您可以使用该列表中的最后两个数字来创建下一个数字。
这种方法看起来会像这样:
>>> def fib_to(n):
... fibs = [0, 1]
... for i in range(2, n+1):
... fibs.append(fibs[-1] + fibs[-2])
... return fibs
...
然后你可以通过执行以下操作获得前20个斐波那契数:
>>> fib_to(20)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765]
或者您可以通过以下方法从前40个斐波那契数列中获取第17个数字:
>>> fib_to(40)[17]
1597
2. 记忆化(相对高级的技术)
另一个加速算法的选择是使用记忆化,不过它比较复杂。由于你已经计算过的值再次出现时需要重新计算,因此你可以把这些已经计算的值保存在字典中,在重新计算之前首先尝试从字典中获取这些值。这就是所谓的“记忆化”。代码可能类似于:
>>> def fib(n, computed = {0: 0, 1: 1}):
... if n not in computed:
... computed[n] = fib(n-1, computed) + fib(n-2, computed)
... return computed[n]
这使你能够轻松地计算大的斐波那契数:
>>> fib(400)
176023680645013966468226945392411250770384383304492191886725992896575345044216019675
事实上,这是一种非常常见的技术,Python 3 包含一个装饰器可以为你执行该操作。我向你展示自动缓存!
import functools
@functools.lru_cache(None)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
这个函数与先前的函数做的事情基本相同,但所有computed相关的东西都由lru_cache修饰器处理。
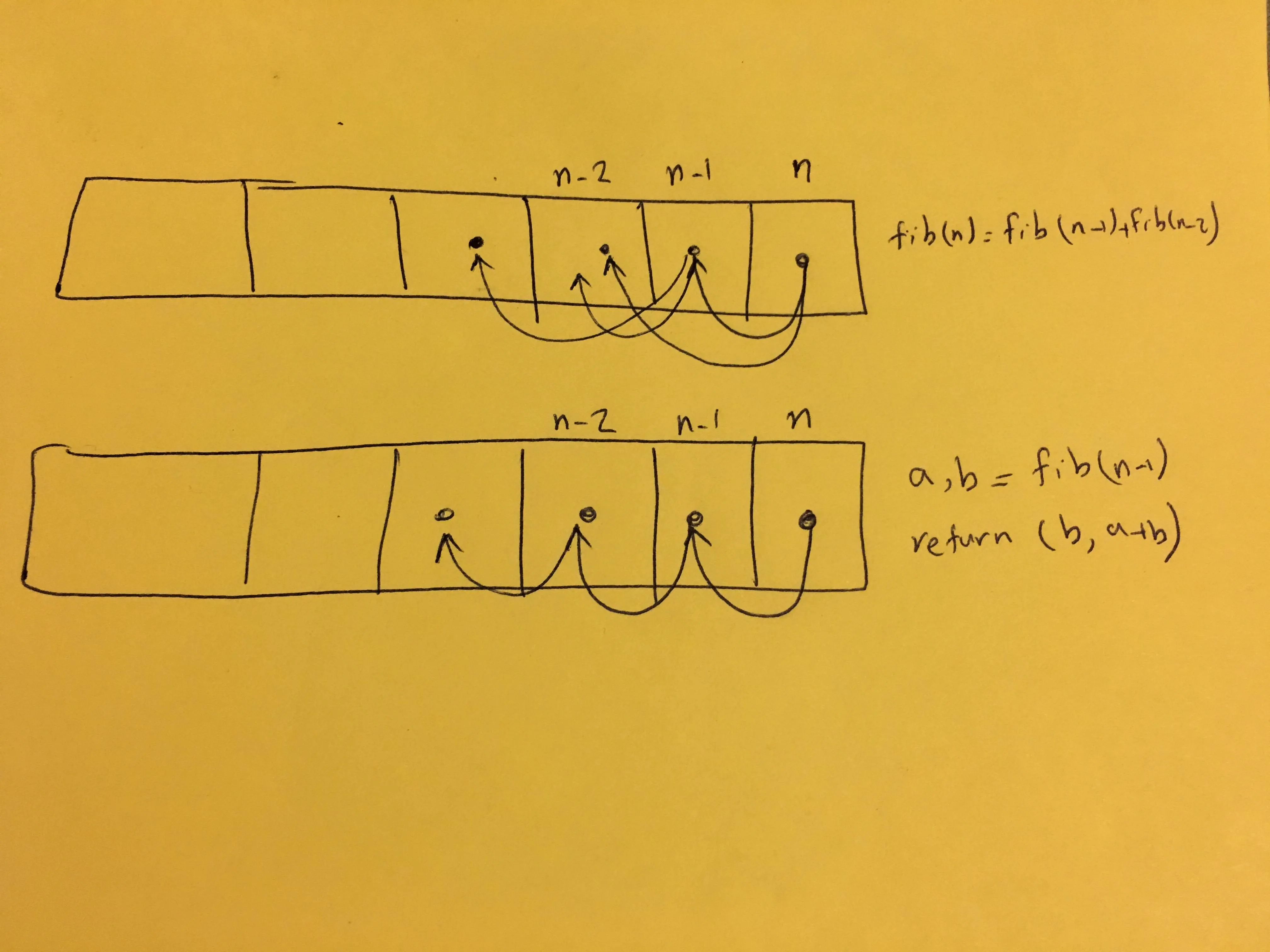
3.仅仅是简单地计数(一个朴素的迭代解决方案)
第三种方法是Mitch建议的,只需计算而不保存列表中的中间值。你可以想象进行如下操作
>>> def fib(n):
... a, b = 0, 1
... for _ in range(n):
... a, b = b, a+b
... return a
我不建议使用这最后两种方法,如果你的目标是创建一个斐波那契数列。使用
fib_to(100) 比
[fib(n) for n in range(101)] 要快得多,因为后者仍然需要从头开始计算列表中的每个数字。
O(log n)的时间复杂度内计算它。请参阅子线性时间内的第n个斐波那契数。 - jfs