我正在运行SQL Server 2012。
我有一个查询,当它被简化到最基本的形式时,看起来像这样:
SELECT COUNT(DISTINCT fullAddress) as quickCount
FROM leads
WHERE yearID >=12 AND yearID <=21
潜在客户表中有大约1.49亿条记录。其中,leadID具有聚集索引,YearID具有非聚集索引,并且包含fullAddress。
当前查询需要大约40秒的时间来运行。我认识到这已经不错了,但在这种情况下,速度还不够快。
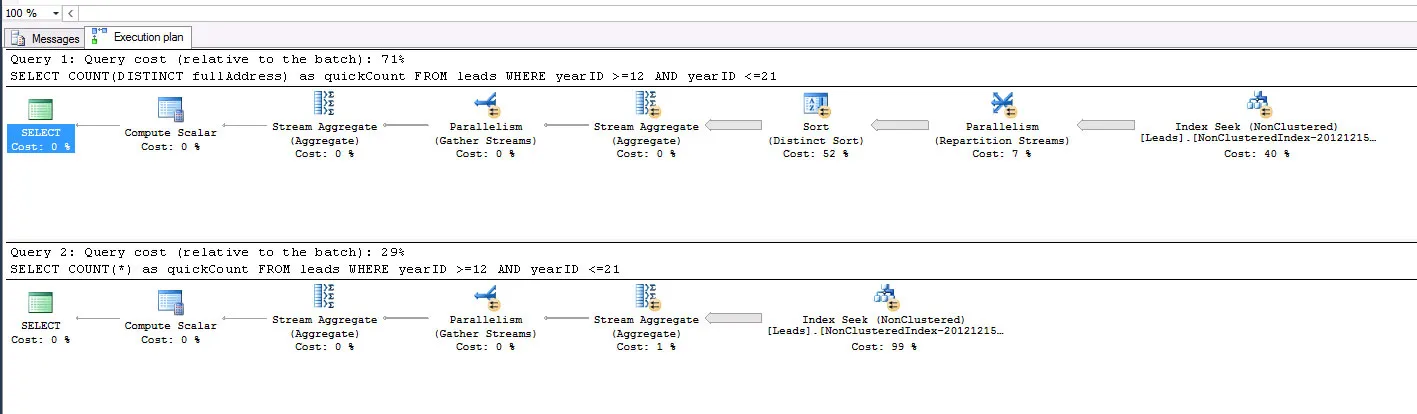
我查看了执行计划,据我所知,大约60%的成本是由于DISTINCT COUNT造成的。
如果我按以下方式运行同样的查询但不使用DISTINCT COUNT:
SELECT COUNT(*) as quickCount
FROM leads
WHERE yearID >=12 AND yearID <=21
运行时间只需要1秒。
不幸的是,我需要得到不同全地址的数量。所以我在尝试想出如何使第一个查询运行更快。
这里是两个查询的执行计划截图:
这是一个链接,可以看到更大的截图 - http://www.sequenzia.com/execPlan.jpg
{kind=link}
从我所能看到的,我的主要问题是独特排序(52%)。
任何关于此的帮助或反馈都将是极好的。
谢谢!
更新
我采纳了Thilo的建议并应用了这个索引:
CREATE INDEX IDX_X ON LEADS(FULLADDRESS, YEARID);
我实际上创建了2个新的测试表,每个表中都有完全相同的100万条记录。我在两个表上都应用了原始索引,然后只在其中一个表上应用了上述索引。现在,当我在相同的执行计划下比较这两个表时,具有上述索引的表略好一些,为48%到52%。这是新的执行计划 - http://www.sequenzia.com/execPlan2.jpg
{kind=link}
这对我有所帮助,但我确实需要更高的性能。还有其他想法吗?