问题:
我按照这里提供的逐步教程训练tesseract ocr来识别新字体。但在第5步和第6步中,并未创建所有所需文件。
我的操作:
我的图像文件是:en.va.exp0.tif
步骤1:创建.box文件 + 更正错误识别的字符
tesseract en.va.exp0.jpg en.va.exp0 batch.nochop makebox
步骤2: 创建 .tr 文件
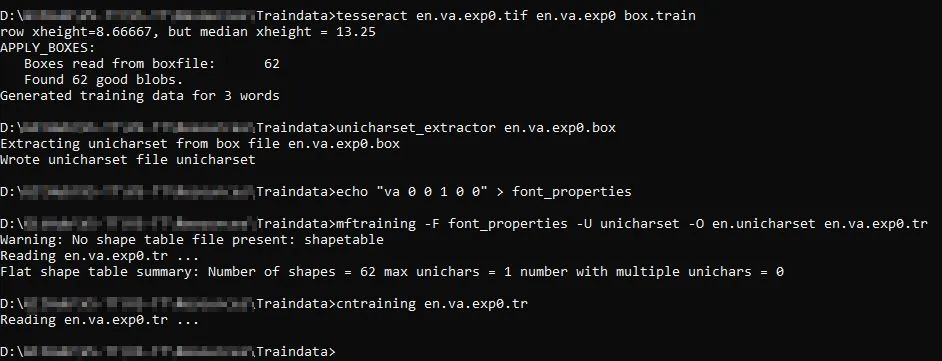
tesseract en.va.exp0.tif en.va.exp0 box.train
第三步:从框文件中提取字符集。
unicharset_extractor en.va.exp0.box
步骤4:创建font_properties文件
echo "va 0 0 1 0 0" > font_properties
步骤5:训练数据
mftraining -F font_properties -U unicharset -O en.unicharset en.va.exp0.tr
步骤6:训练数据
cntraining en.va.exp0.tr
据我所知,第5步应该创建4个文件:shapetable、inttemp、pffmtable和normproto。但只有shapetable文件被创建了。因此,第6步也不起作用(我认为它根本什么都没做)。 材料: 如果需要更多的解释或材料,我会补充并提前感谢。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
mftraining无限运行并没有返回任何结果。你设法解决了吗? - XxX