我想要识别车牌上的字符。如何在Ubuntu 16.04上训练Tesseract-ocr以识别相应的车牌?因为我不熟悉训练,请帮我创建一个'traineddata'文件以识别车牌号码。
以下是需要翻译的内容: 我有1000张车牌图像。请看一下。任何帮助都将不胜感激。
所以我尝试了以下命令:
但是它会出现错误。
以下是需要翻译的内容: 我有1000张车牌图像。请看一下。任何帮助都将不胜感激。
所以我尝试了以下命令:
tesseract [langname].[fontname].[expN].[file-extension] [langname].[fontname].[expN] batch.nochop makebox
tesseract eng.arial.plate3655.png eng.arial.plate3655 batch.nochop makebox
但是它会出现错误。
Tesseract Open Source OCR Engine v4.1.0-rc1-56-g7fbd with Leptonica
Error, cannot read input file eng.arial.plate3655.png: No such file or directory
Error during processing.
之后我尝试了以下操作
tesseract plate4.png eng.arial.plate4 batch.nochop makebox
在某些盘中它能够正常工作。但是在第二步骤中,我遇到了错误。
附有截图。
第四个盘的图像用于训练。

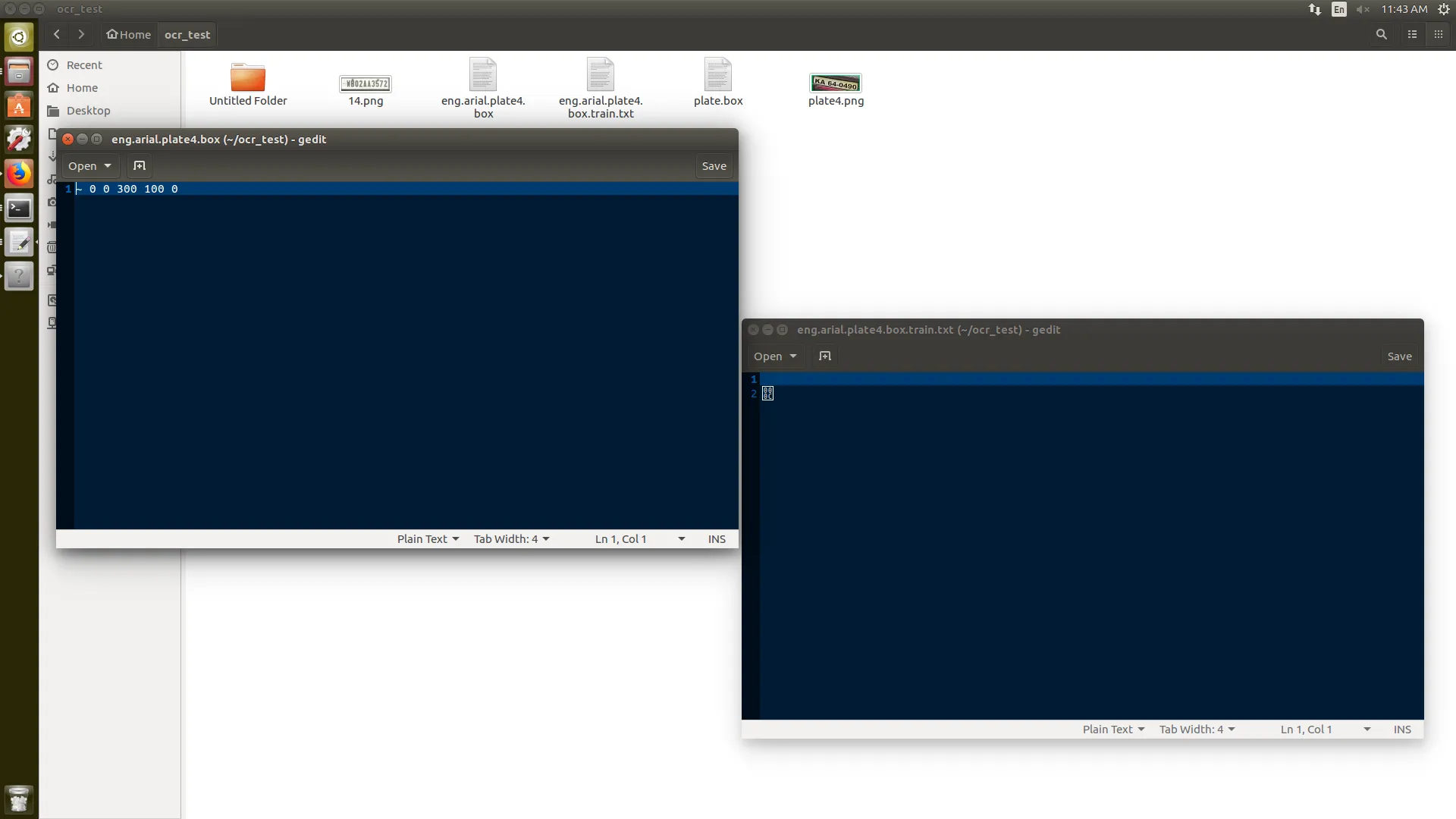
第1步骤和第2步骤在终端中显示。
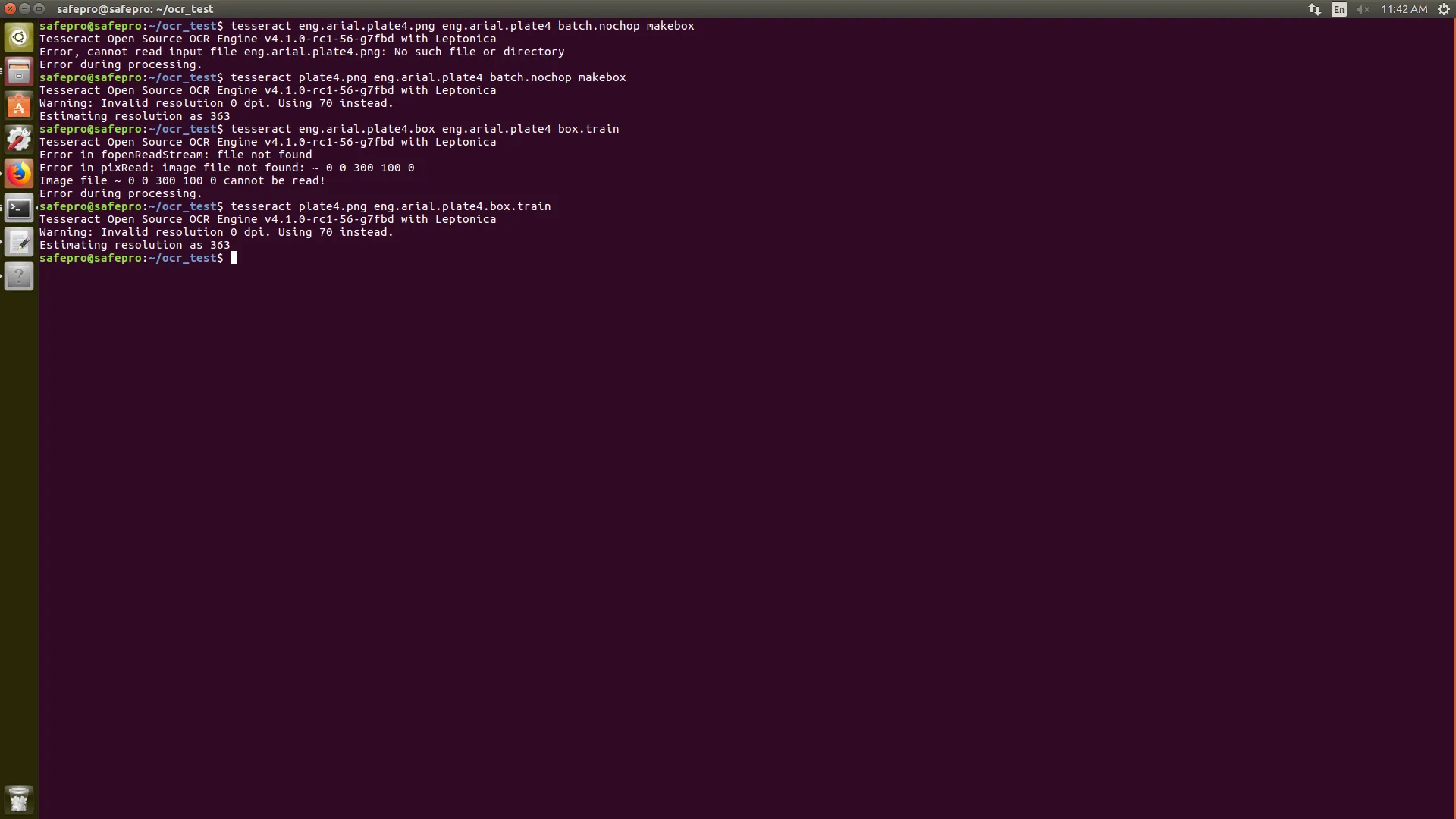
第1步骤和第2步骤后生成的文件。
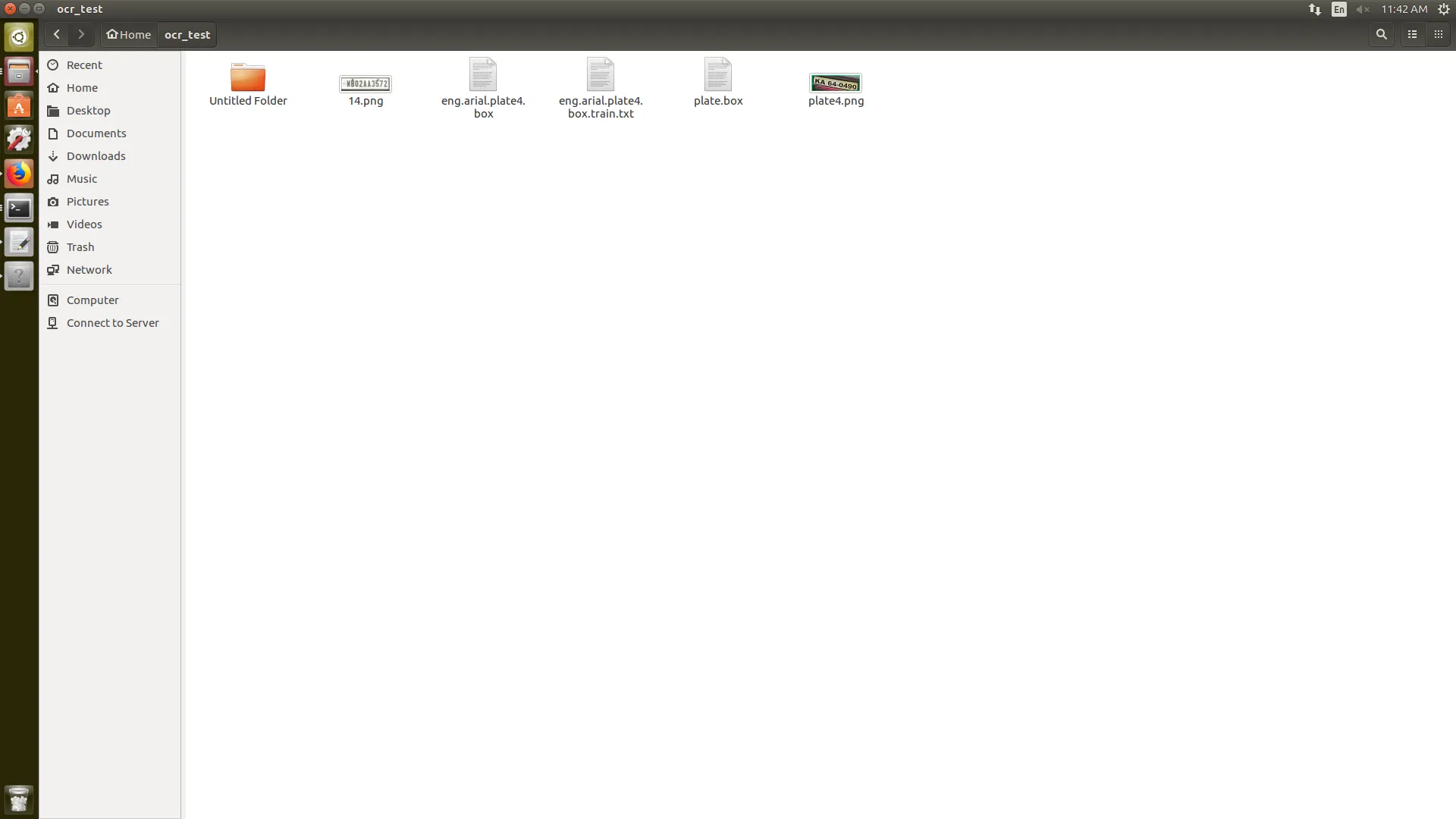
第1步骤和第2步骤后生成文件的内容。