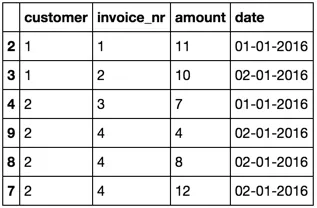
我有一份发给客户的发票清单。然而,有时会发送错误的发票,之后又被取消。我的Pandas数据框架看起来像这样,只是更大(约300万行)。
index | customer | invoice_nr | amount | date
---------------------------------------------------
0 | 1 | 1 | 10 | 01-01-2016
1 | 1 | 1 | -10 | 01-01-2016
2 | 1 | 1 | 11 | 01-01-2016
3 | 1 | 2 | 10 | 02-01-2016
4 | 2 | 3 | 7 | 01-01-2016
5 | 2 | 4 | 12 | 02-01-2016
6 | 2 | 4 | 8 | 02-01-2016
7 | 2 | 4 | -12 | 02-01-2016
8 | 2 | 4 | 4 | 02-01-2016
... | ... | ... | ... | ...
... | ... | ... | ... | ...
现在,我想要删除所有满足以下条件的行:
customer,invoice_nr和date相同,但是amount的值相反。发票的更正总是在同一天进行,具有相同的发票号。发票号唯一绑定到客户,并且始终对应于一个交易(可以由多个组件组成,例如对于
customer = 2,invoice_nr = 4)。发票的更正仅发生在更改已收费用或将amount拆分为较小的组件时。因此,在相同的invoice_nr上不会重复取消值。
非常感谢您提供如何编写此程序的任何帮助。
invoice_nr和date作为dict键来读取吗?那么我该如何处理具有相同invoice_nr和date的多行数据呢? - Niels Alebregtse