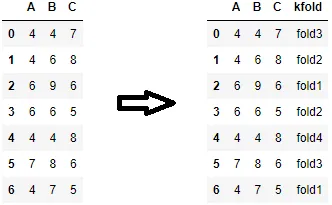
我已经使用以下代码获取了训练集和测试集的索引。
df = pandas.read_pickle(filepath + filename)
kf = KFold(n_splits = n_splits, shuffle = shuffle, random_state =
randomState)
result = next(kf.split(df), None)
#train can be accessed with result[0]
#test can be accessed with result[1]
我想知道是否有更快的方法,可以使用我检索到的行索引将它们分别分隔成两个数据框。