我有以下数据框。
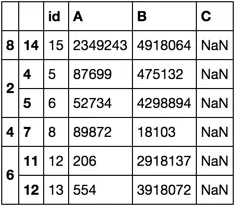
id A B C 1 34353 917998 x 2 34973 980340 x 3 87365 498097 x 4 98309 486547 x 5 87699 475132 6 52734 4298894 7 8749267 4918066 x 8 89872 18103 9 589892 4818086 y 10 765 4063 y 11 32369 418165 y 12 206 2918137 13 554 3918072 14 1029 1918051 x 15 2349243 4918064
对于每组空行,例如5,6,我想创建一个新的数据框。需要生成多个数据框,如下所示:
id A B 5 87699 475132 6 52734 4298894
id A B 8 89872 18103
id A B 12 206 2918137 13 554 3918072
id A B 15 2349243 4918064