I have a dataframe like this:
df_test = pd.DataFrame({'ID1':['A','A','A','A','A','A','B','B','B','B'],
'ID2':['a','a','a','aa','aaa','aaa','b','b','bb','bb'],
'ID3':['c1','c2','c3','c4','c5','c6','c7','c8','c9','c10'],
'condition':['','!','','!','','','!','','','!']})
{kind=link}
我希望按ID1将它们分组。结果数据框应该像这样(count_condition表示每个ID2组中'!'的数量):
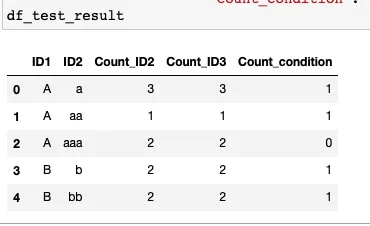
df_test_result = pd.DataFrame({'ID1':['A','A','A','B','B'],
'ID2':['a','aa','aaa','b','bb'],
'Count_ID2':[3,1,2,2,2],
'Count_ID3':[3,1,2,2,2],
'Count_condition': [1,1,0,1,1]})
{kind=link}
我尝试使用groupby和agg来获得这个结果,但我无法获取每个组中'!'的数量。这是我的命令:
df_test_result = df_test.groupby(['ID1','ID2']).agg({'ID2':'count','ID3':'nunique','condition':'count'})
如果有一种像这样错误的命令:
df_test = df_test.groupby(['ID1','ID2']).agg({'ID2':'count','ID3':'nunique','condition' == '!':'count'})
pd.NamedAgg,您可以使用元组:Count_ID2=('ID2', 'count')等等。;) - mozway