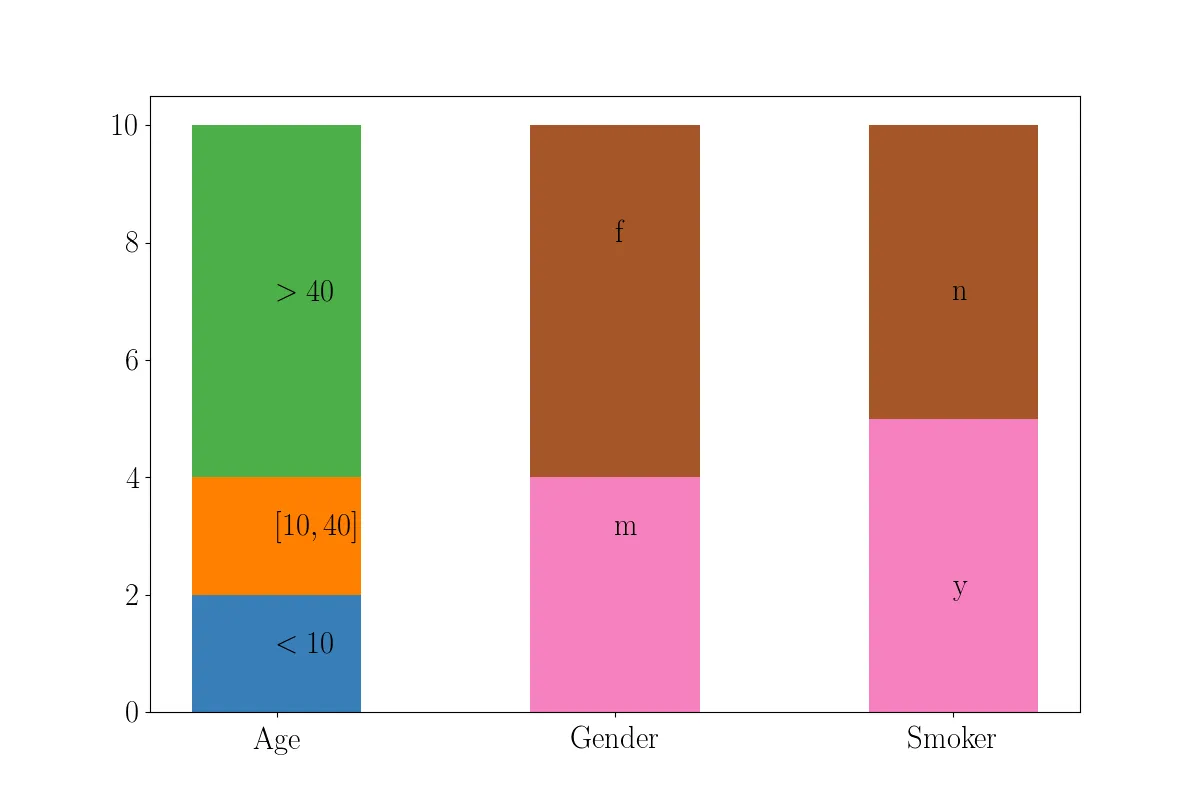
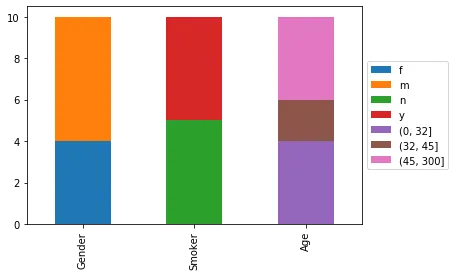
我有以下代码用于绘制数据库中某些主题的直方图:
import matplotlib.pyplot as plt
attr_info = {
'Gender': ['m', 'f', 'm', 'm', 'f', 'm', 'm', 'f', 'm', 'f'],
'Age': [9, 43, 234, 23, 2, 95, 32, 63, 58, 42],
'Smoker': ['y', 'n', 'y', 'y', 'n', 'n', 'n', 'n', 'y', 'y']
}
bin_info = {key: None for key in attr_info}
bin_info['Age'] = 10
for name, a_info in attr_info.items():
plt.figure(num=name)
counts, bins, _ = plt.hist(a_info, bins=bin_info[name], color='blue', edgecolor='black')
plt.margins(0)
plt.title(name)
plt.xlabel(name)
plt.ylabel("# Subjects")
plt.yticks(range(0, 11, 2))
plt.grid(axis='y')
plt.tight_layout(pad=0)
plt.show()
这段代码可以运行,但它会在单独的直方图中绘制每个属性的分布。我想实现的是类似于这样的效果:
 我知道plt.hist有一个堆叠参数,但那似乎是用于稍微不同的用途,即将相同的属性叠放在不同的主题类型上。例如,你可以绘制一个直方图,其中每个整个条代表某个年龄范围,而条本身则是吸烟者和非吸烟者在不同颜色中的堆栈。我还没有能够弄清楚如何使用它来将不同的属性叠放在每个条形图中,并正确标记为图像中的那样。
我知道plt.hist有一个堆叠参数,但那似乎是用于稍微不同的用途,即将相同的属性叠放在不同的主题类型上。例如,你可以绘制一个直方图,其中每个整个条代表某个年龄范围,而条本身则是吸烟者和非吸烟者在不同颜色中的堆栈。我还没有能够弄清楚如何使用它来将不同的属性叠放在每个条形图中,并正确标记为图像中的那样。