在R中,是否有一种方法可以生成具有最小距离的随机坐标?
例如,我想避免以下情况
x <- c(0,3.9,4.1,8)
y <- c(1,4.1,3.9,7)
plot(x~y)
在R中,是否有一种方法可以生成具有最小距离的随机坐标?
例如,我想避免以下情况
x <- c(0,3.9,4.1,8)
y <- c(1,4.1,3.9,7)
plot(x~y)
spatstat有用于执行此操作的函数。rHardcore是一个完美的采样器,但如果你想要高强度的点和大硬核距离,它可能无法在有限时间内终止...该分布可以作为马尔可夫链的极限得到,rmh.default让您运行具有给定Gibbs模型作为其不变分布的马尔可夫链。这将在有限时间内完成,但仅提供近似分布的实现。rmh.default中,您还可以在固定点数的条件下模拟。请注意,在有限的框中进行采样时,对于给定的硬核半径,能够适合多少个点当然是有上限的,而且越接近这个极限,从分布中正确地采样就越成问题。library(spatstat)
beta <- 100; R = 0.1
win <- square(1) # Unit square for simulation
X1 <- rHardcore(beta, R, W = win) # Exact sampling -- beware it may run forever for some par.!
plot(X1, main = paste("Exact sim. of hardcore model; beta =", beta, "and R =", R))

minnndist(X1) # Observed min. nearest neighbour dist.
#> [1] 0.102402
model <- rmhmodel(cif="hardcore", par = list(beta=beta, hc=R), w = win)
X2 <- rmh(model)
#> Checking arguments..determining simulation windows...Starting simulation.
#> Initial state...Ready to simulate. Generating proposal points...Running Metropolis-Hastings.
plot(X2, main = paste("Approx. sim. of hardcore model; beta =", beta, "and R =", R))

minnndist(X2) # Observed min. nearest neighbour dist.
#> [1] 0.1005433
X3 <- rmh(model, control = rmhcontrol(p=1), start = list(n.start = 42))
#> Checking arguments..determining simulation windows...Starting simulation.
#> Initial state...Ready to simulate. Generating proposal points...Running Metropolis-Hastings.
plot(X3, main = paste("Approx. sim. given n =", 42))

minnndist(X3) # Observed min. nearest neighbour dist.
#> [1] 0.1018068
X 是指数分布,公式为 r+X。可能需要一个新的问题来提供更多细节。 - Ege Rubak好的,那么这样怎么样?你只需生成没有限制的随机数对,然后删除那些太接近的数。这可以是一个很好的开始:
minimumDistancePairs <- function(x, y, minDistance){
i <- 1
repeat{
distance <- sqrt((x-x[i])^2 + (y-y[i])^2) < minDistance # pythagorean theorem
distance[i] <- FALSE # distance to oneself is always zero
if(any(distance)) { # if too close to any other point
x <- x[-i] # remove element from x
y <- y[-i] # and remove element from y
} else { # otherwise...
i = i + 1 # repeat the procedure with the next element
}
if (i > length(x)) break
}
data.frame(x,y)
}
minimumDistancePairs(
c(0,3.9,4.1,8)
, c(1,4.1,3.9,7)
, 1
)
会导致
x y
1 0.0 1.0
2 4.1 3.9
3 8.0 7.0
需要注意的是,无论您如何解决问题,这些数字都不再是随机的。
> set.seed(1)
>
> x <- rnorm(2)
> y <- rnorm(2)
> (x[1]-x[2])^2+(y[1]-y[2])^2
[1] 6.565578
> while((x[1]-x[2])^2+(y[1]-y[2])^2 > 1) {
+ x <- rnorm(2)
+ y <- rnorm(2)
+ }
> (x[1]-x[2])^2+(y[1]-y[2])^2
[1] 0.9733252
>
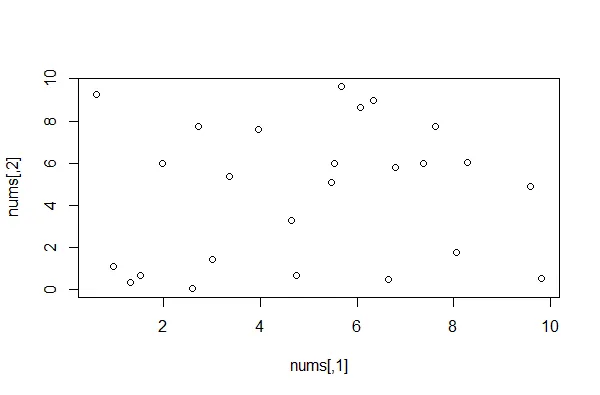
rand.separated <- function(n,x0,x1,y0,y1,d,trials = 1000){
for(i in 1:trials){
nums <- cbind(runif(n,x0,x1),runif(n,y0,y1))
if(min(dist(nums)) >= d) return(nums)
}
return(NA) #no luck
}
[x0,x1]x[y0,y1]中重复抽取大小为n的样本,并且如果样本不符合要求就会被抛弃。作为安全措施,trials可以防止无限循环。如果难以找到解决方案或者n很大,您可能需要增加或减少trials。> set.seed(2018)
> nums <- rand.separated(25,0,10,0,10,0.2)
> plot(nums)
几乎瞬间运行并生成:
我不确定你在问什么。
如果你想要随机坐标,可以在这里找到。
c(
runif(1,max=y[1],min=x[1]),
runif(1,max=y[2],min=x[2]),
runif(1,min=y[3],max=x[3]),
runif(1,min=y[4],max=x[4])
)