我正试图在Python中随机生成一堆点,用于测试K-means聚类算法。以下是我的代码:
N = 100
random_x0 = np.random.randn(N) + (np.random.randint(0,100) * np.random.randint(1,4))
random_x1 = np.random.randn(N) + (np.random.randint(0,100) * np.random.randint(1,4))
random_x2 = np.random.randn(N) + (np.random.randint(0,100) * np.random.randint(1,4))
random_y0 = np.random.randn(N) + (np.random.randint(0,100) * np.random.randint(1,4))
random_y1 = np.random.randn(N) + (np.random.randint(0,100) * np.random.randint(1,4))
random_y2 = np.random.randn(N) + (np.random.randint(0,100) * np.random.randint(1,4))
可以想象,每组random_x[index]坐标都与其y对应项匹配。
(random_x0, random_y0), (random_x1, random_y1), (random_x2, random_y2)
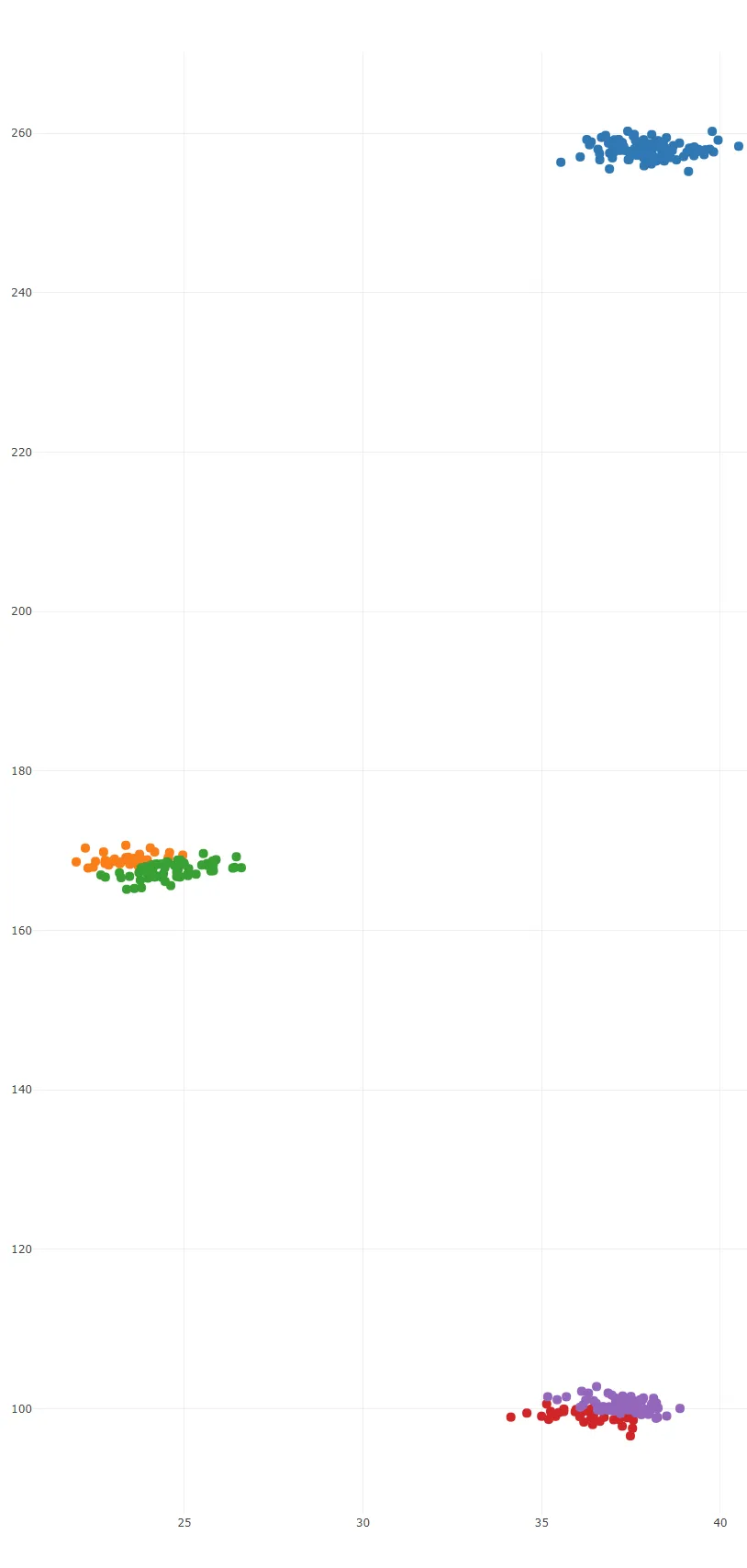
由于我正在测试聚类算法,我希望我的数据点有一定程度的聚集...但这似乎太多了。我尝试添加一个1-100之间的随机数,然后将其乘以一个1-4之间的随机数....我做错了什么,才会得到如此一致的随机结果?
randint调用)仅用于移动聚类,而不是使它们扩散。如果要使它们扩散,请将您的随机向量(来自randn)乘以一些静态缩放因子--可能类似于:random_x0 = scale * np.random.randn(N)。 离原点最远的点将会离原点scale的距离。这里的注释可能有所帮助。 - jedwards