x.contiguous() 对于张量 x 做什么?
PyTorch中的.contiguous()是什么意思?
209
- MBT
3
跨帖:https://www.quora.com/unanswered/Why-do-we-need-to-call-contiguous-in-Pytorch - Charlie Parker
论坛中的答案:https://discuss.pytorch.org/t/contigious-vs-non-contigious-tensor/30107/2 - Charlie Parker
什么情况下我们需要调用“contiguous”? - Charlie Parker
8个回答
345
PyTorch中有一些张量操作不会改变张量的内容,但会改变数据组织方式。这些操作包括:
narrow(),view(),expand()和transpose()
例如:当您调用transpose()时,PyTorch不会生成一个新张量与新布局,它只是修改张量对象中的元信息,以便偏移量和步幅描述所需的新形状。 在这个例子中,转置后的张量和原始张量共享同样的内存:
x = torch.randn(3,2)
y = torch.transpose(x, 0, 1)
x[0, 0] = 42
print(y[0,0])
# prints 42
这里涉及到“连续”(contiguous)的概念。在上面的例子中,x是连续的,但y不是,因为其内存布局与从头开始创建的相同形状张量的内存布局不同。请注意,“连续”这个词有点误导人,因为张量的内容并没有分散在不连续的内存块中。在这里,字节仍然分配在一个内存块中,但元素的顺序不同!
当你调用contiguous()时,它实际上会复制张量,以便其元素在内存中的顺序与使用相同数据从头创建的顺序相同。
通常情况下,您无需担心此问题。通常可以安全地假定一切都有效,并等待您收到RuntimeError:input is not contiguous,而PyTorch期望连续张量添加对contiguous()的调用。
- Shital Shah
14
7我无法确定地回答这个问题,但我的猜测是,一些 PyTorch 代码使用了 C++ 实现的高性能向量化操作,并且这些代码不能使用张量元信息中指定的任意偏移量/步长。不过这只是我的猜测。 - Shital Shah
3为什么被调用者不能自己调用
contiguous()函数? - information_interchange6另一个受欢迎的张量操作是“permute”,它也可能返回非“连续”的张量。 - Oleg
5什么情况下我们需要调用
contiguous 呢? - Charlie Parker显示剩余9条评论
57
如果一个一维数组[0, 1, 2, 3, 4]的元素在内存中相邻排列,就称它是连续的,就像下面这样:

如果存储它的内存区域看起来像这样,则不是连续的:

对于二维数组或更高维度的数组,元素也必须相邻,但是顺序遵循不同的约定。让我们考虑下面的二维数组:
>>> t = torch.tensor([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]])

如果行存储在一起,像这样,内存分配就是C连续的:

>>> t.is_contiguous()
True
PyTorch的张量类方法 stride() 给出在每个维度中获取下一个元素所需跳过的字节数。
>>> t.stride()
(4, 1)
我们需要跳过4个字节才能到达下一行,但只需要一个字节就可以到达同一行中的下一个元素。
正如其他答案所述,一些Pytorch操作不会改变内存分配,只会改变元数据。
例如,转置方法。让我们来转置张量:

内存分配没有改变:

>>> t.T.stride()
(1, 4)
我们需要跳过1个字节才能到达下一行,跳过4个字节才能到达同一行中的下一个元素。张量不再是C连续的(实际上是Fortran连续:每列存储在相邻位置)
>>> t.T.is_contiguous()
False
contiguous()将重新排列内存分配,以使张量为C连续:

>>> t.T.contiguous().stride()
(3, 1)
一些操作,例如 reshape() 和 view(),会对底层数据的连续性产生不同的影响。
- Pierre
46
如来自pytorch文档:
contiguous() → Tensor
返回一个连续的tensor,包含与self tensor相同的数据。如果self tensor是连续的,则此函数返回self tensor。
在这里,“contiguous”不仅意味着在内存中是连续的,而且还意味着在内存中与索引顺序相同:例如,进行转置不会改变内存中的数据,它只是更改从索引到内存指针的映射,如果您随后应用contiguous(),它将更改内存中的数据,以便从索引到内存位置的映射是规范化的。
- patapouf_ai
10
1谢谢你的回答!你能告诉我为什么/何时需要数据是连续的吗?仅仅是性能,还是其他原因?PyTorch是否需要一些操作要求数据是连续的?
为什么目标需要连续而输入不需要呢? - MBT
4显然,PyTorch要求损失函数的目标在内存中是连续的,但神经网络的输入不需要满足这个要求。 - patapouf_ai
2非常感谢!我认为我明白了,我注意到contiguous()函数在forward函数中也适用于输出数据(当然以前是输入),因此在计算损失时,输出和目标都是连续的。
非常感谢! - MBT
有什么情况下我们需要调用
contiguous 函数呢? - Charlie Parker1如果你需要它而不使用它,torch会给出需要的错误提示。一些张量操作需要连续的张量,但并非全部。 - patapouf_ai
显示剩余5条评论
23
tensor.contiguous()将创建张量的一个副本,并将副本中的元素以连续的方式存储在内存中。当我们首先对张量进行转置(transpose)然后再reshape(view)它时,通常需要使用contiguous()函数。首先,让我们创建一个连续的张量:
aaa = torch.Tensor( [[1,2,3],[4,5,6]] )
print(aaa.stride())
print(aaa.is_contiguous())
#(3,1)
#True
stride()返回(3,1)的意思是:当沿着第一维(逐行)移动每个步长时,我们需要在内存中移动3个步长。当沿着第二维(逐列)移动每个步长时,我们需要在内存中移动1个步长。这表明张量中的元素是连续存储的。
现在我们尝试对张量应用一些函数:
bbb = aaa.transpose(0,1)
print(bbb.stride())
print(bbb.is_contiguous())
#(1, 3)
#False
ccc = aaa.narrow(1,1,2) ## equivalent to matrix slicing aaa[:,1:3]
print(ccc.stride())
print(ccc.is_contiguous())
#(3, 1)
#False
ddd = aaa.repeat(2,1) # The first dimension repeat once, the second dimension repeat twice
print(ddd.stride())
print(ddd.is_contiguous())
#(3, 1)
#True
## expand is different from repeat.
## if a tensor has a shape [d1,d2,1], it can only be expanded using "expand(d1,d2,d3)", which
## means the singleton dimension is repeated d3 times
eee = aaa.unsqueeze(2).expand(2,3,3)
print(eee.stride())
print(eee.is_contiguous())
#(3, 1, 0)
#False
fff = aaa.unsqueeze(2).repeat(1,1,8).view(2,-1,2)
print(fff.stride())
print(fff.is_contiguous())
#(24, 2, 1)
#True
好的,我们可以发现 transpose()、narrow() 和 tensor 切片,以及 expand() 会使生成的张量不连续。有趣的是,repeat() 和 view() 不会使其不连续。那么现在的问题是:如果我使用不连续的张量会发生什么?
答案是,view() 函数不能应用于不连续的张量。这可能是因为 view() 要求张量被连续存储,以便它可以在内存中快速进行重塑。例如:
bbb.view(-1,3)
我们将会得到这个错误:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-63-eec5319b0ac5> in <module>()
----> 1 bbb.view(-1,3)
RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Call .contiguous() before .view(). at /pytorch/aten/src/TH/generic/THTensor.cpp:203
bbb.contiguous().view(-1,3)
#tensor([[1., 4., 2.],
[5., 3., 6.]])
- avatar
1
如果contiguous创建了一个副本,那么这是否会阻止autodiff通过原始张量计算梯度? - Rylan Schaeffer
10
与之前的答案一样,contiguous() 函数分配连续的内存块,这对于我们将张量传递给 C 或 C++ 后端代码时非常有帮助,其中张量被作为指针传递。
- p. vignesh
9
被接受的答案非常好,我试图模仿transpose()函数的效果。我创建了两个函数,可以检查samestorage()和contiguous。
进一步注意到,最终有创建连续和非连续张量的方法。有些方法可以在相同的存储器上操作,而一些方法如flip()将在返回之前创建一个新的存储器(即:克隆张量)。
检查器代码:
def samestorage(x,y):
if x.storage().data_ptr()==y.storage().data_ptr():
print("same storage")
else:
print("different storage")
def contiguous(y):
if True==y.is_contiguous():
print("contiguous")
else:
print("non contiguous")
我检查后得到了以下结果表格:
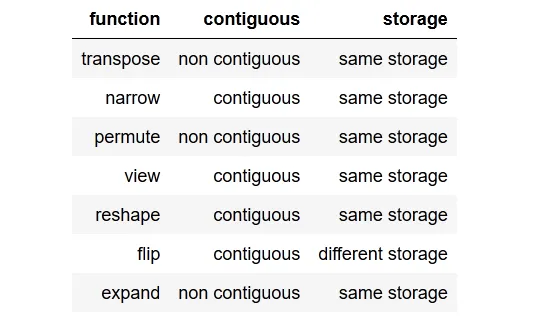
view(),我们需要对其进行reshape(),或者我们也可以调用.contiguous().view()。x = torch.randn(3,2)
y = x.transpose(0, 1)
y.view(6) # RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
x = torch.randn(3,2)
y = x.transpose(0, 1)
y.reshape(6)
x = torch.randn(3,2)
y = x.transpose(0, 1)
y.contiguous().view(6)
进一步注意到,最终有创建连续和非连续张量的方法。有些方法可以在相同的存储器上操作,而一些方法如flip()将在返回之前创建一个新的存储器(即:克隆张量)。
检查器代码:
import torch
x = torch.randn(3,2)
y = x.transpose(0, 1) # flips two axes
print("\ntranspose")
print(x)
print(y)
contiguous(y)
samestorage(x,y)
print("\nnarrow")
x = torch.randn(3,2)
y = x.narrow(0, 1, 2) #dim, start, len
print(x)
print(y)
contiguous(y)
samestorage(x,y)
print("\npermute")
x = torch.randn(3,2)
y = x.permute(1, 0) # sets the axis order
print(x)
print(y)
contiguous(y)
samestorage(x,y)
print("\nview")
x = torch.randn(3,2)
y=x.view(2,3)
print(x)
print(y)
contiguous(y)
samestorage(x,y)
print("\nreshape")
x = torch.randn(3,2)
y = x.reshape(6,1)
print(x)
print(y)
contiguous(y)
samestorage(x,y)
print("\nflip")
x = torch.randn(3,2)
y = x.flip(0)
print(x)
print(y)
contiguous(y)
samestorage(x,y)
print("\nexpand")
x = torch.randn(3,2)
y = x.expand(2,-1,-1)
print(x)
print(y)
contiguous(y)
samestorage(x,y)
- prosti
2
torch.narrow的返回值并不总是连续的,这取决于维度。
In [145]: x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
In [146]: torch.narrow(x, 1, 1, 2).is_contiguous()
Out[146]: False``` - Rafael@ Saibō,随意使用这个提示进行更新。 - prosti
3
一个张量,其值在存储中从最右边的维度开始排列(即对于2D张量,沿行移动)被定义为“连续的”。 连续的张量很方便,因为我们可以有效地按顺序访问它们,而不必在存储中跳来跳去(由于现代CPU上的内存访问方式,改进数据局部性可以提高性能)。 当然,这种优势取决于算法的访问方式。
在PyTorch中,一些张量操作仅适用于连续张量,例如“view”,[...]。 在这种情况下,PyTorch将抛出有关的异常,并要求我们显式调用连续函数。 值得注意的是,如果张量已经连续,则调用“contiguous”将不会产生任何影响(也不会降低性能)。
请注意,这比计算机科学中“连续”一词的一般用法(即连续且有序)更具体。
例如,给定一个张量:
[[1, 2]
[3, 4]]
| 在内存中的存储方式 | PyTorch contiguous? |
通常在内存空间中是"contiguous"吗? |
|---|---|---|
1 2 3 4 0 0 0 |
✅ | ✅ |
1 3 2 4 0 0 0 |
❌ | ✅ |
1 0 2 0 3 0 4 |
❌ | ❌ |
- iacob
0
据我所知,这是一个更简洁的答案:
连续是指张量的内存布局与其宣传的元数据或形状信息不对齐的术语。
在我看来,“连续”这个词是一个令人困惑/误导的术语,因为在正常情况下,它意味着内存没有分散在不连续的块中(即“连续/连接/连续”)。
一些操作可能需要这种连续性属性,出于某种原因(最可能是在GPU等方面的效率)。
请注意,.view是另一个可能引起此问题的操作。查看以下代码,我通过简单调用连续函数来解决了这个问题(而不是典型的转置问题引起的RNN不满意输入的例子):
# normal lstm([loss, grad_prep, train_err]) = lstm(xn)
n_learner_params = xn_lstm.size(1)
(lstmh, lstmc) = hs[0] # previous hx from first (standard) lstm i.e. lstm_hx = (lstmh, lstmc) = hs[0]
if lstmh.size(1) != xn_lstm.size(1): # only true when prev lstm_hx is equal to decoder/controllers hx
# make sure that h, c from decoder/controller has the right size to go into the meta-optimizer
expand_size = torch.Size([1,n_learner_params,self.lstm.hidden_size])
lstmh, lstmc = lstmh.squeeze(0).expand(expand_size).contiguous(), lstmc.squeeze(0).expand(expand_size).contiguous()
lstm_out, (lstmh, lstmc) = self.lstm(input=xn_lstm, hx=(lstmh, lstmc))
我曾经遇到的错误:
RuntimeError: rnn: hx is not contiguous
来源/资源:
- Charlie Parker
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 3 在PyTorch中,param_groups是什么意思?
- 3 PyTorch张量中的“大于”运算符“>”是什么意思?
- 19 PyTorch函数中的下划线后缀是什么意思?
- 25 PyTorch中的data.norm() < 1000是什么意思?
- 259 在PyTorch中,model.eval()是什么意思?
- 117 Pytorch中的"unsqueeze"是什么意思?
- 3 在 PyTorch 的 nn.EmbeddingBag 中,offsets 是什么意思?
- 337 PyTorch中的.view()是什么意思?
- 3 PyTorch中的BatchNorm2d的running_mean/running_var是什么意思?
- 3 在PyTorch中,“register”是什么意思?