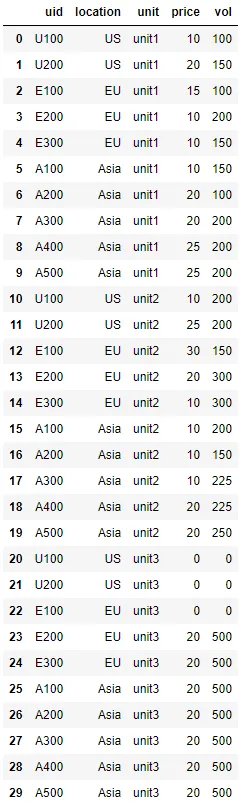
假设我有以下的df。我想将价格列和数量列合并,以便所有价格在一列中,所有数量在另一列中。我还想要第三列来确定价格级别。例如,unit1、unit2和unit3。
结果为:
假设我有以下的df。我想将价格列和数量列合并,以便所有价格在一列中,所有数量在另一列中。我还想要第三列来确定价格级别。例如,unit1、unit2和unit3。
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
'uid': ['U100', 'U200', 'E100', 'E200', 'E300', 'A100', 'A200', 'A300', 'A400', 'A500'],
'location': ['US', 'US', 'EU', 'EU', 'EU', 'Asia', 'Asia', 'Asia', 'Asia', 'Asia'],
'unit1_price': [10, 20, 15, 10, 10, 10, 20, 20, 25, 25],
'unit1_vol': [100, 150, 100, 200, 150, 150, 100, 200, 200, 200],
'unit2_price': [10, 25, 30, 20, 10, 10, 10, 10, 20, 20],
'unit2_vol': [200, 200, 150, 300, 300, 200, 150, 225, 225, 250],
'unit3_price': [0, 0, 0, 20, 20, 20, 20, 20, 20, 20],
'unit3_vol': [0, 0, 0, 500, 500, 500, 500, 500, 500, 500]
}
)
df
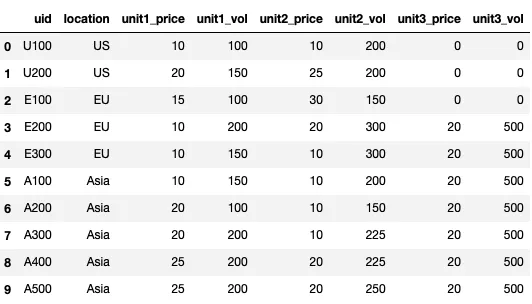
这就是最终的df应该看起来的样子:
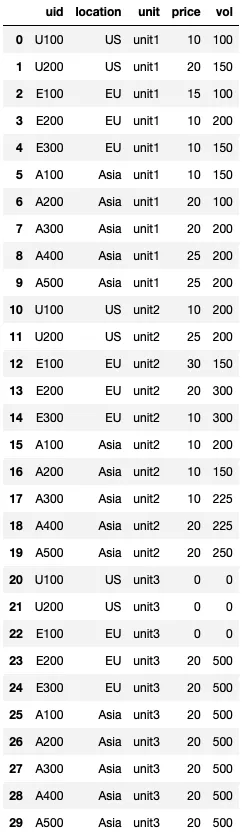
我尝试使用了melt,我认为几乎已经得到了正确的答案。
pd.melt(df, id_vars=['uid', 'location'], value_vars=['unit1_price', 'unit1_vol', 'unit2_price', 'unit2_vol', 'unit3_price', 'unit3_vol'])
使用 melt 函数后,这是部分数据框的样子:
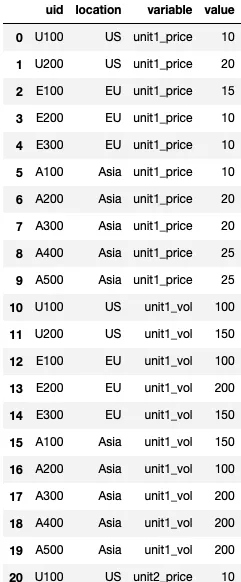
上述问题在于“volume”和“price”位于同一列中,但我希望它们分别位于两个不同的列中。
我是否使用了正确的函数?