我想使用tensorflow以数值稳定的方式计算比率
如果导数计算为
这相当于
有推荐的方法来缓解这些问题吗?如果不想依赖于自动微分,是否可能明确定义表达式在tensorflow中的导数?
f = - a / b的导数,但当a和b很小时(使用32位浮点表示时小于<1e-20),会遇到问题。当然,f的导数是df_db = a / b ** 2,但由于运算符优先级,分母中的平方首先被计算,导致下溢并导致梯度未定义。如果导数计算为
df_db = (a / b) / b,则不会发生下溢,梯度将被定义,如下图所示,它显示了梯度作为a = b函数的情况。蓝线对应于tensorflow可以计算导数的域。橙色线对应于分母下溢产生无限梯度的域。绿线对应于分母上溢产生零梯度的域。在两个有问题的域中,可以使用上述修改后的表达式计算梯度。
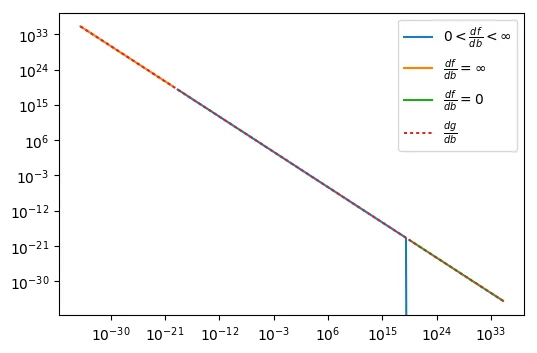
g = exp(log(a) - log(b))
这相当于
f,但会产生不同的tensorflow图。但如果我想计算更高阶导数,我会遇到同样的问题。可以在此处找到重现问题的代码。有推荐的方法来缓解这些问题吗?如果不想依赖于自动微分,是否可能明确定义表达式在tensorflow中的导数?

gradient_override_map。 - Yaroslav Bulatov