我试图使用data.table包在64位的R上加载一个大型CSV文件(226M行,38列)。该文件在磁盘上的大小约为27Gb。我在一台具有64GB RAM的服务器上执行此操作。我关闭了几乎所有其他内容,并开始了一个全新的R/Rstudio会话,因此当我启动fread时,只使用了2GB的内存。随着读取过程进行,我看到内存使用量上升到约45.6 Gb,然后我遇到了可怕的Error: cannot allocate vector of size 1.7 Gb。然而,仍然剩下超过18Gb可用。是否可能在18Gb的RAM中没有1.7Gb的连续块?这是否与已提交的大小有关(我承认我没有完全理解),如果是这样,是否有任何方法可以将提交的大小最小化以便留出足够的空间?
该列表包括我想要随时间汇总和总结某些统计数据的用户群体的历史记录。使用fread中的select,我已经能够导入38列中的子集,因此我不至于完全失误,但这意味着如果我需要处理其他变量,我就需要挑选,可能最终会遇到相同的错误。
对于我拥有的设置,是否有其他方法可以将整个数据集加载到内存中,还是我只需要继续导入子集或转移到大数据友好型平台?
谢谢您。
读取前的内存使用情况

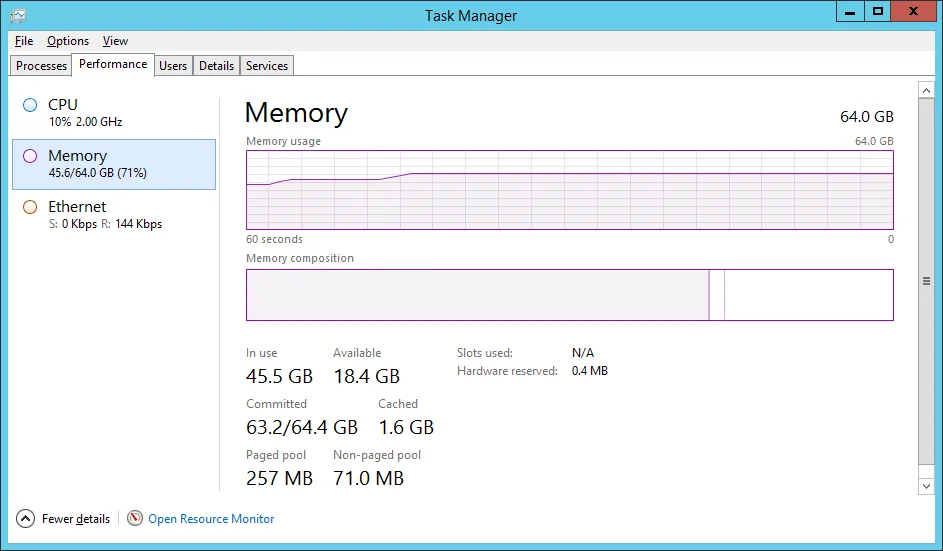
失败时的内存使用情况
会话信息
R version 3.3.0 Patched (2016-05-11 r70599)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows Server >= 2012 x64 (build 9200)
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] data.table_1.9.6
loaded via a namespace (and not attached):
[1] tools_3.3.0 chron_2.3-47
iotools包,它有一些功能可能对这种情况有所帮助。 - lmomemory.limit()来查看R实际可用的内存有多少。 - Psidom