此文章的目的是了解如何使用
我想使用以下方法为每个二级货币添加名为daily_added_value的新列:
然而,这会引发一个关键错误:
继续下面的答案仍存在问题 添加每日收益有效
apply()和shift()向MultiIndex.DataFrame中的一个层级添加列。
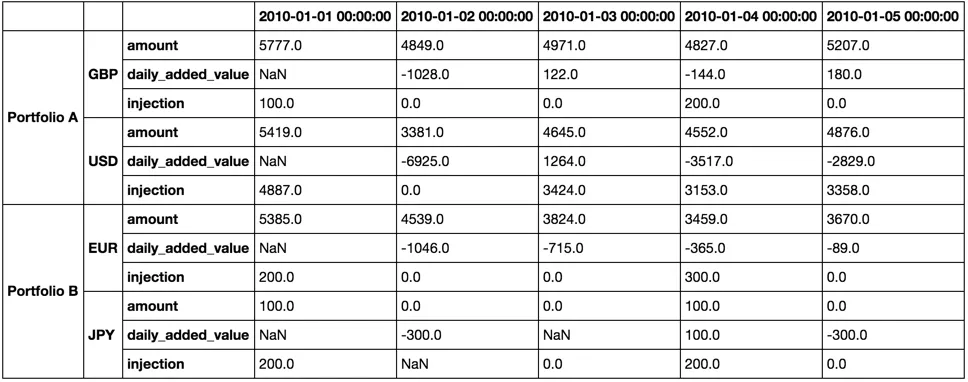
创建DataFrame:
import pandas as pd
df = pd.DataFrame(
[
[5777, 100, 5385, 200, 5419, 4887, 100, 200],
[4849, 0, 4539, 0, 3381, 0, 0, ],
[4971, 0, 3824, 0, 4645, 3424, 0, 0, ],
[4827, 200, 3459, 300, 4552, 3153, 100, 200, ],
[5207, 0, 3670, 0, 4876, 3358, 0, 0, ],
],
index=pd.to_datetime(['2010-01-01',
'2010-01-02',
'2010-01-03',
'2010-01-04',
'2010-01-05']),
columns=pd.MultiIndex.from_tuples(
[('Portfolio A', 'GBP', 'amount'), ('Portfolio A', 'GBP', 'injection'),
('Portfolio B', 'EUR', 'amount'), ('Portfolio B', 'EUR', 'injection'),
('Portfolio A', 'USD', 'amount'), ('Portfolio A', 'USD', 'injection'),
('Portfolio B', 'JPY', 'amount'), ('Portfolio B', 'JPY', 'injection')])
).sortlevel(axis=1)
print df
我想使用以下方法为每个二级货币添加名为daily_added_value的新列:
def do_nothing(group):
return group
def calc_daily_added_value(group):
g = (group['amount'] - group['amount'].shift(periods=1, freq=None, axis=0)
-df['injection'].shift(periods=1, freq=None, axis=0)).round(decimals=2)
g.index = ['daily_added_value']
return g
pd.concat([df.T.groupby(level=0).apply(f).T for f in [calc_daily_added_value,do_nothing ]], axis=1).sort_index(axis=1)
然而,这会引发一个关键错误:
KeyError: 'amount'
calc_daily_added_value()方法的正确语法是什么?
继续下面的答案仍存在问题 添加每日收益有效
dav = df.loc[:, pd.IndexSlice[:, :, 'daily_added_value']]
amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
dr = (dav.values / amount.shift()) * 100
dr.columns.set_levels(['daily_return'], level=2, inplace=True)
df = pd.concat([df, dr], axis=1).sortlevel(axis=1)
添加累计复合回报失败
dr = df.loc[:, pd.IndexSlice[:, :, 'daily_return']]
drc = 100*((1+dr / 100).cumprod()-1)
drc.columns.set_levels(['daily_return_cumulative'], level=2, inplace=True)
df = pd.concat([df, drc], axis=1).sort_index(axis=1)
df.head()
这里失败的原因是缺少了“.values”,但是如果我添加了它,它就变成了一个数组?
不过奇怪的是,drc实际上是一个形状正确等等的DataFrame,并且似乎包含了正确的结果。
这个错误发生在这一行:
drc.columns.set_levels(['daily_return_cumulative'], level=2, inplace=True)
错误是ValueError:在第2级上,标签max(2)> = level(1)的长度。注意:此索引处于不一致状态
如何将索引放回一致状态?
drc.columns.set_levels(['daily_return_cumulative'], level=2, inplace=True, verify_integrity = False),但是这会产生一个algos.cp35-win_amd64.pyd未处理的异常。 - ctrl-alt-delete