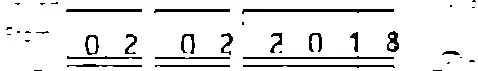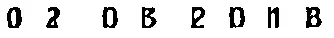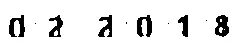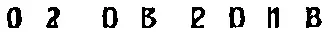我有一些日期需要使用Tesseract识别。但是,很多日期中的数字与日期框中的线条混合在一起,如下所示:



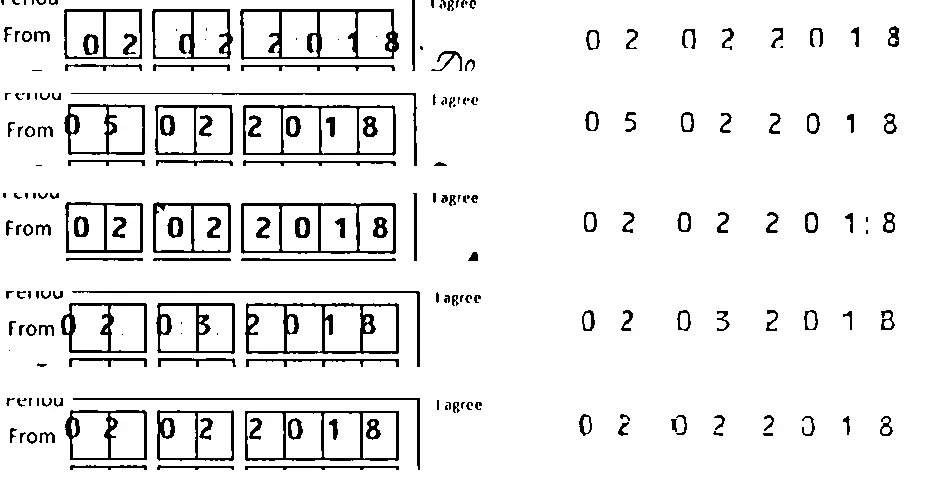
此外,这里有一张我可以成功使用Tesseract识别的好图片:
这是我的代码:
import os
import cv2
from matplotlib import pyplot as plt
import subprocess
import numpy as np
from PIL import Image
def show(img):
plt.figure(figsize=(20,20))
plt.imshow(img,cmap='gray')
plt.show()
def sort_contours(cnts, method="left-to-right"):
# initialize the reverse flag and sort index
reverse = False
i = 0
# handle if we need to sort in reverse
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
# handle if we are sorting against the y-coordinate rather than
# the x-coordinate of the bounding box
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# construct the list of bounding boxes and sort them from top to
# bottom
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
cnts, boundingBoxes = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b:b[1][i], reverse=reverse))
# return the list of sorted contours and bounding boxes
return cnts, boundingBoxes
def tesseract_it(contours,main_img, label,delete_last_contour=False):
min_limit, max_limit = (1300,1700)
idx =0
roi_list = []
slist= set()
for cnt in contours:
idx += 1
x,y,w,h = cv2.boundingRect(cnt)
if label=='boxes':
roi=main_img[y+2:y+h-2,x+2:x+w-2]
else:
roi=main_img[y:y+h,x:x+w]
if w*h > min_limit and w*h < max_limit and w>10 and w< 50 and h>10 and h<50:
if (x,y,w,h) not in slist: # Stops from identifying repeted contours
roi = cv2.resize(roi,dsize=(45,45),fx=0 ,fy=0, interpolation = cv2.INTER_AREA)
roi_list.append(roi)
slist.add((x,y,w,h))
if not delete_last_contour:
vis = np.concatenate((roi_list),1)
else:
roi_list.pop(-1)
vis = np.concatenate((roi_list),1)
show(vis)
# Tesseract the final image here
# ...
image = 'bad_digit/1.jpg'
# image = 'bad_digit/good.jpg'
specimen_orig = cv2.imread(image,0)
specimen = cv2.fastNlMeansDenoising(specimen_orig)
# show(specimen)
kernel = np.ones((3,3), np.uint8)
# Now we erode
specimen = cv2.erode(specimen, kernel, iterations = 1)
# show(specimen)
_, specimen = cv2.threshold(specimen, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# show(specimen)
specimen_canny = cv2.Canny(specimen, 0, 0)
# show(specimen_canny)
specimen_blank_image = np.zeros((specimen.shape[0], specimen.shape[1], 3))
_,specimen_contours, retr = cv2.findContours(specimen_canny.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE )
# print(len(specimen_contours))
cv2.drawContours(specimen_blank_image, specimen_contours, -1, 100, 2)
# show(specimen_blank_image)
specimen_blank_image = np.zeros((specimen.shape[0], specimen.shape[1], 3))
specimen_sorted_contours, specimen_bounding_box = sort_contours(specimen_contours)
output_string = tesseract_it(specimen_sorted_contours,specimen_orig,label='boxes',)
# return output_string
好的图像输出如下:

然而,对于那些线条与数字融合在一起的情况,我的输出结果看起来像这样:

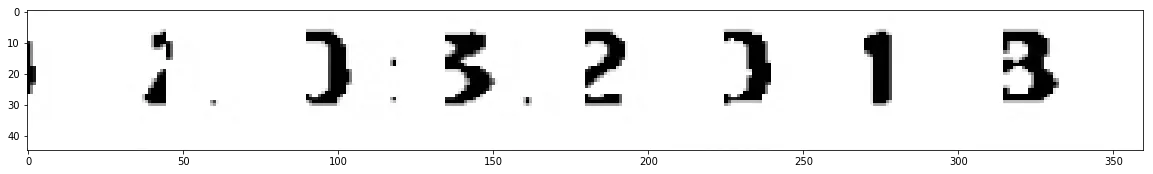
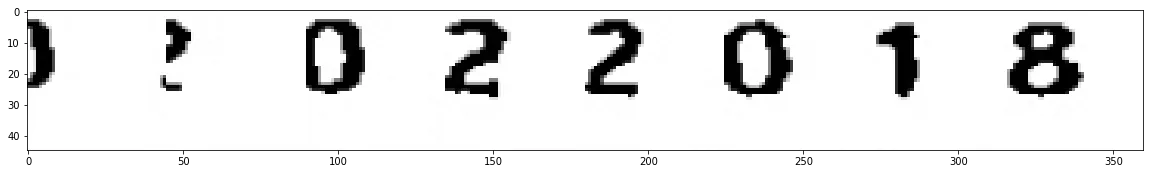
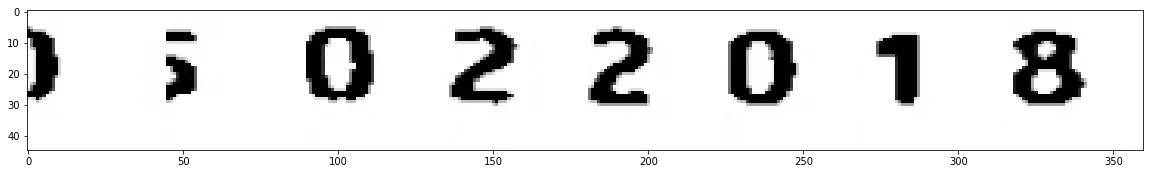
这些对 Tesseract 来说并不起作用。 我想知道是否有一种方法可以去除线条并仅保留数字。
我也尝试了以下方法: https://docs.opencv.org/3.2.0/d1/dee/tutorial_moprh_lines_detection.html
但似乎在我附加的图像上表现不佳。
我还尝试使用 imagemagick:
convert original.jpg \
\( -clone 0 -threshold 50% -negate -statistic median 200x1 \) \
-compose lighten -composite \
\( -clone 0 -threshold 50% -negate -statistic median 1x200 \) \
-composite output.jpg
结果还算公平,但是删除的线有点切断数字,如下所示:
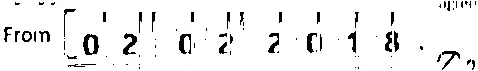
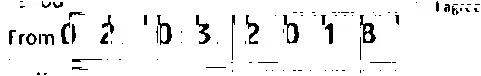
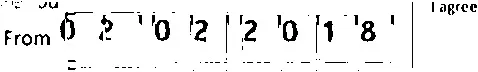
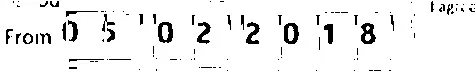
我能不能用更好的方法解决这个问题?我的最终目标是扫描这些数字,所以最后的图像确实需要很清晰。