我正在尝试用图表设置最常见的单词,但我遇到了一个问题,因为语言是阿拉伯语,与格式不匹配。
fig, ax = plt.subplots(figsize=(12, 10))
sns.barplot(x="word", y="freq", data=word_counter_df, palette="PuBuGn_d", ax=ax)
plt.show();
我尝试了使用AST进行解码,但它无法与绘图相匹配。
import ast
fig, ax = plt.subplots(figsize=(12, 10))
sns.barplot(x="word", y="freq", data=word_counter_df.apply(ast.literal_eval).str.decode("utf-8"), palette="PuBuGn_d", ax=ax)
plt.show();
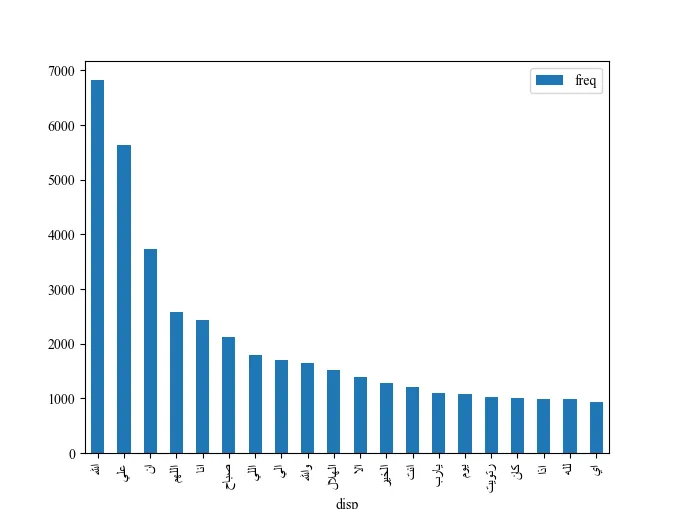
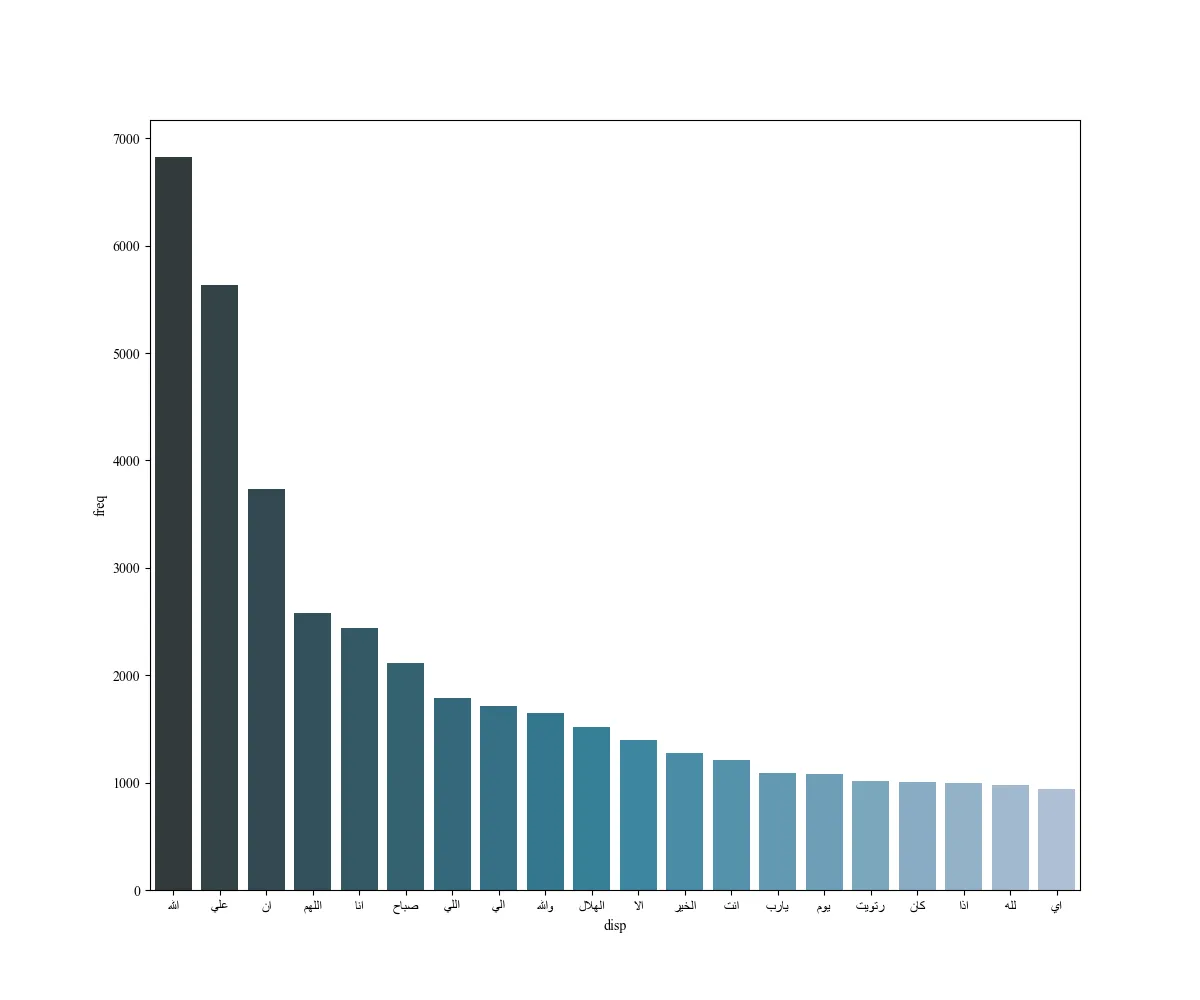
word_counter_df的样子:
<class 'pandas.core.frame.DataFrame'>
word freq
0 الله 6829
1 علي 5636
2 ان 3732
3 اللهم 2575
4 انا 2436
5 صباح 2115
6 اللي 1792
7 الي 1709
8 والله 1645
9 الهلال 1520
10 الا 1394
11 الخير 1276
12 انت 1209
13 يارب 1089
14 يوم 1082
15 رتويت 1019
16 كان 1004
17 اذا 994
18 لله 982
19 اي 939
使用以下错误信息返回空图:
ValueError: ('节点或字符串格式不正确:0 الله \n1 علي \n2 ان \n3 اللهم \n4 انا \n5 صباح \n6 اللي \n7
الي \n8 والله \n9 الهلال\n10 الا \n11 الخير \n12
انت \n13 يارب \n14 يوم \n15 رتويت \n16 كان \n17
اذا \n18 لله \n19 اي \nName: word, dtype: object', '出现于单词索引处')
{kind=link}
word_counter_df数据框的摘录。 - Diziet Asahi