我似乎找不到这个例子。 我很难确定是否需要使用索引、布尔掩码或直接合并。 我已尝试了各种变体的.isin和.between,但都没有成功。
情景:
Two dataFrames with no common index:
df1 = pd.DataFrame({'printId': ['x','y', 'z', 'a'],'locCode': [0.9, 1.5, 4.0, 7.8]}) df2 = pd.DataFrame({'assetId': ['1','1a', '2', '2a', '3', '4'], 'locStart': [0.9, 0.9, 1, 1, 4, 8], 'locEnd': [0.9, 0.9, 3, 3, 5, 13]})
df1:
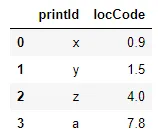
df2:
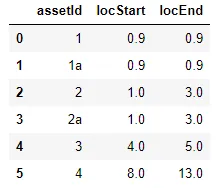
需要这个:
df3 = pd.DataFrame({'printId': ['x','x', 'y', 'y', 'z', 'a', 'NaN'], 'locCode': ['0.9', '0.9', '1.5', '1.5', '4.0', '7.8', 'NaN'], 'assetID': ['1', '1a', '2', '2a', '3', 'NaN', '4'], 'locStart': ['0.9', '0.9', '1.0', '1.0', '4.0', 'NaN', '8.0'], 'locEnd':['0.9', '0.9', '3.0', '3.0', '4.0', 'NaN', '13.0']})
df3
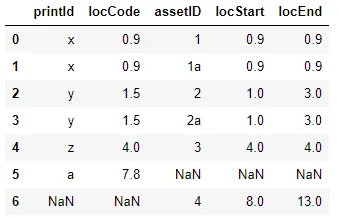
职业技术人员如何解决这个问题?
编辑: 经过仔细检查,原来的答案不可行。
- 当
df2中有重复的locStart/End记录,但具有唯一的assetID(第0行、1行和第2行、3行),df1将无法合并。