正如Remus所说,这取决于你的工作量。
然而,我想解决被接受答案中一个误导性的方面。
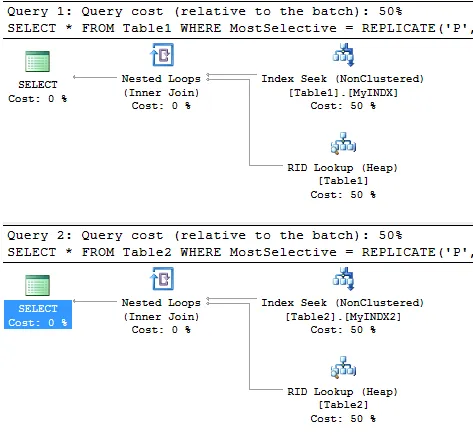
对于在索引的所有列上执行等值搜索的查询,没有显着的差异。
下面创建了两个表,并使用相同的数据填充它们。唯一的区别是其中一个的键按最具选择性到最不具选择性的顺序排序,而另一个则相反。
CREATE TABLE Table1(MostSelective char(800), SecondMost TINYINT, Least CHAR(1), Filler CHAR(4000) null);
CREATE TABLE Table2(MostSelective char(800), SecondMost TINYINT, Least CHAR(1), Filler CHAR(4000) null);
CREATE NONCLUSTERED INDEX MyINDX on Table1(MostSelective,SecondMost,Least);
CREATE NONCLUSTERED INDEX MyINDX2 on Table2(Least,SecondMost,MostSelective);
INSERT INTO Table1 (MostSelective, SecondMost, Least)
output inserted.* into Table2
SELECT TOP 26 REPLICATE(CHAR(number + 65),800), number/5, '~'
FROM master..spt_values
WHERE type = 'P' AND number >= 0
ORDER BY number;
现在对这两个表进行查询...
SELECT *
FROM Table1
WHERE MostSelective = REPLICATE('P', 800)
AND SecondMost = 3
AND Least = '~';
SELECT *
FROM Table2
WHERE MostSelective = REPLICATE('P', 800)
AND SecondMost = 3
AND Least = '~';
......两个查询都使用一个细节索引,并且它们的成本完全相同。
所接受答案中的ASCII艺术实际上并不是索引结构。下面是Table1的索引页(单击图像以全尺寸打开)。
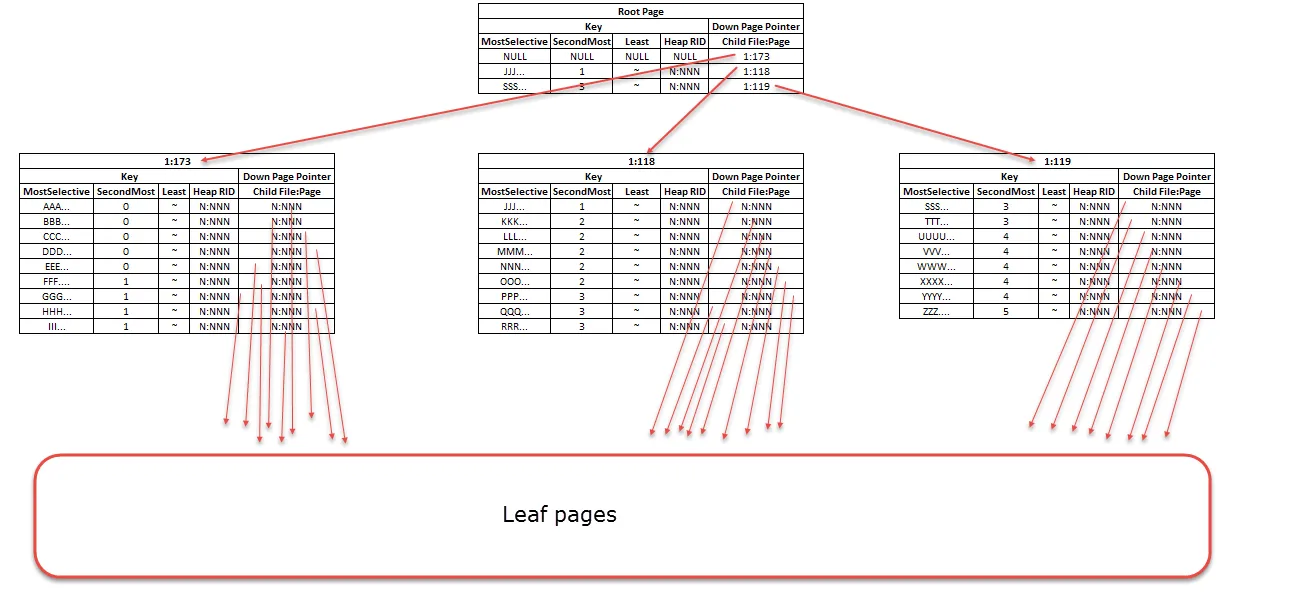
索引页面包含包含整个键的行(在这种情况下,实际上会添加一个额外的键列作为行标识符,因为索引未声明为唯一,但可以忽略此处可以找到更多信息)。
对于上面的查询,SQL Server不关心列的选择性。它对根页面进行二进制搜索,并发现Key (PPP...,3,~ )大于等于>=(JJJ...,1,~ )和< (SSS...,3,~ ),因此应读取页面1:118。然后,在该页面上执行关键字条目的二进制搜索并定位要导航到的叶页面。
按选择性顺序修改索引不会影响二进制搜索的预期关键字比较次数或需要导航以执行索引查找的页面数。充其量,它可能会稍微加快关键字比较本身的速度。
但有时,将选择性最高的索引排在第一位对于负载中的其他查询可能是有意义的。
例如,如果工作负载包含以下两种形式的查询。
SELECT * ... WHERE MostSelective = 'P'
SELECT * ...WHERE Least = '~'
上述索引对它们中的任何一个都不够覆盖。
MostSelective 具有足够的选择性,可以制定一个值得进行查找和查阅的计划,但针对
Least 的查询则不是这样。
然而,这种情况(在复合索引的前导列的子集上进行非覆盖索引查找)只是可以通过索引帮助的查询类别之一。如果您从未实际通过单独的
MostSelective 或
MostSelective, SecondMost 的组合搜索,而总是通过所有三列的组合进行搜索,则这种理论优势对您毫无用处。
相反,如下查询:
SELECT MostSelective,
SecondMost,
Least
FROM Table2
WHERE Least = '~'
ORDER BY SecondMost,
MostSelective
如果将通常预设的顺序倒过来,会对查询有帮助 - 因为它可以覆盖查询,支持查找并以所需的顺序返回行。
因此,这是一个经常重复的建议,但最多只是关于潜在受益于其他查询的启发式规则 - 它不能替代实际查看你自己的工作负载。