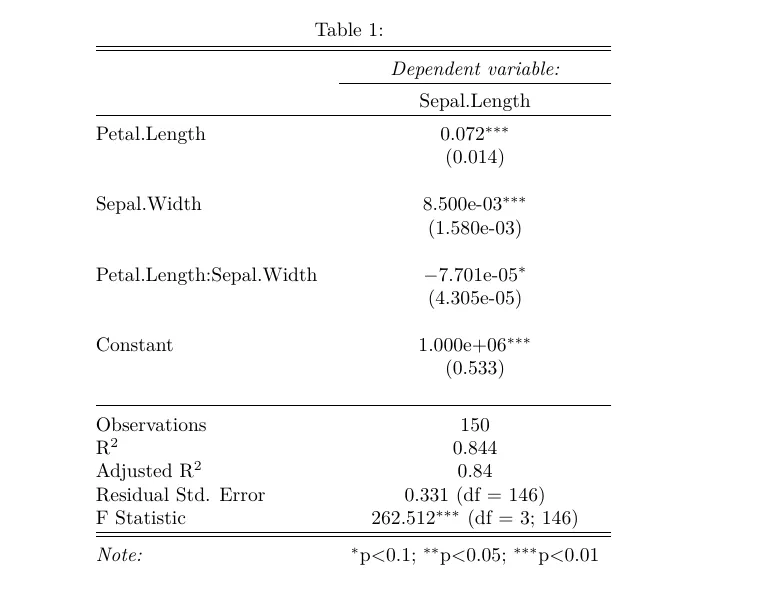
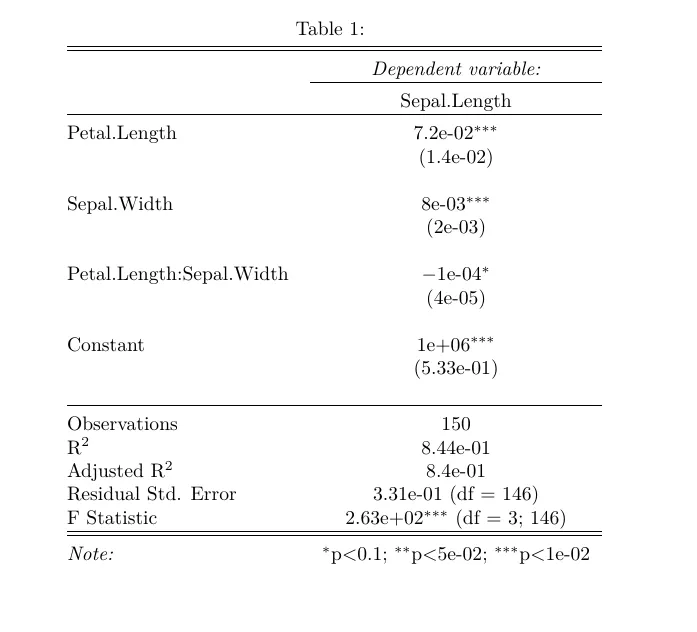
另一种使用stargazer获取科学计数法的强大方法是通过修改
digit.separator参数。该选项允许用户指定分隔小数的字符(在大多数地区通常为点
.)。我们可以篡改此参数,将唯一可识别的字符串插入到任何要使用正则表达式查找的数字中。以这种方式搜索数字的优点是,我们只能找到与stargazer输出中的数值相对应的数字。即,没有可能同时匹配变量名称的数字(例如X_12345)或作为latex格式化代码的一部分的数字(例如
\hline \\[-1.8ex])。在下面的例子中,我使用字符串
::::,但任何我们在表格中找不到的唯一字符串(如哈希)都可以。最好避免在标识符标记中有任何特殊的正则表达式字符,因为这会稍微复杂一些。
使用this other answer中的示例模型m1。
mark = '::::'
star = stargazer(m1, header = F, decimal.mark = mark, digit.separator = '')
replace_numbers = function(x, low=0.01, high=1e3, digits = 3, scipen=-7, ...) {
x = gsub(mark,'.',x)
x.num = as.numeric(x)
ifelse(
(x.num >= low) & (x.num < high),
round(x.num, digits = digits),
prettyNum(x.num, digits=digits, scientific = scipen, ...)
)
}
reg = paste0("([0-9.\\-]+", mark, "[0-9.\\-]+)")
cat(gsubfn(reg, ~replace_numbers(x), star), sep='\n')

更新
如果您想确保科学计数法中保留尾随零,则可以使用sprintf而不是prettyNum。
像这样
replace_numbers = function(x, low=0.01, high=1e3, digits = 3) {
x = gsub(mark,'.',x)
x.num = as.numeric(x)
form = paste0('%.', digits, 'e')
ifelse(
(abs(x.num) >= low) & (abs(x.num) < high),
round(x.num, digits = digits),
sprintf(form, x.num)
)
}