我已经使用Linux perf 一段时间来进行应用程序分析。通常,被分析的应用程序非常复杂,因此人们往往只是简单地接受报告的计数器值,只要与基于第一原理的预期相差不大就行了。
然而,最近我对一些微不足道的64位汇编程序进行了分析——足够微不足道,以至于可以几乎精确地计算出各种计数器的预期值,结果发现
例如,考虑以下循环:
这将简单地循环
这是
哦。我们看到的不是大约4,000,000,000条指令和1,000,000,000个分支,而是多出了神秘的410,032条指令和71,277个分支。总会有“额外”的指令,但数量会有些不同 - 例如,后续运行分别有421K、563K和464K个额外指令。您可以通过构建我的 简单的github项目 在您的系统上运行此项测试。
好的,那么你可能会猜测这几十万个额外的指令只是固定的应用程序设置和拆卸成本(用户空间设置是非常小的,但可能有隐藏的东西)。那么我们试试
现在有大约490万个额外的指令,比之前增加了10倍,与循环计数的增加成比例。您可以尝试各种计数器-所有与CPU相关的计数器都显示类似的比例增加。为了保持简单,让我们重点关注指令计数。使用“:u”和“:k”后缀分别测量用户和内核计数,显示在内核中产生的计数几乎占所有额外事件的比例:
最后,我注意到执行的内核指令数量似乎与运行时间1(或CPU时间)成正比,而不是与执行的指令数量成正比。为了测试这一点,我使用了一个类似的程序,但用一个
然而,最近我对一些微不足道的64位汇编程序进行了分析——足够微不足道,以至于可以几乎精确地计算出各种计数器的预期值,结果发现
perf stat存在过多计数的情况。例如,考虑以下循环:
.loop:
nop
dec rax
nop
jne .loop
这将简单地循环
n 次,其中 n 是 rax 的初始值。循环的每次迭代执行 4 条指令,因此您可以期望执行 4 * n 指令,再加上一些小的固定开销,用于进程启动和终止以及在进入循环之前设置 n 的一小段代码。这是
n = 1,000,000,000 的 (典型的) perf stat 输出:~/dev/perf-test$ perf stat ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
301.795151 task-clock (msec) # 0.998 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.007 K/sec
1,003,144,430 cycles # 3.324 GHz
4,000,410,032 instructions # 3.99 insns per cycle
1,000,071,277 branches # 3313.742 M/sec
1,649 branch-misses # 0.00% of all branches
0.302318532 seconds time elapsed
哦。我们看到的不是大约4,000,000,000条指令和1,000,000,000个分支,而是多出了神秘的410,032条指令和71,277个分支。总会有“额外”的指令,但数量会有些不同 - 例如,后续运行分别有421K、563K和464K个额外指令。您可以通过构建我的 简单的github项目 在您的系统上运行此项测试。
好的,那么你可能会猜测这几十万个额外的指令只是固定的应用程序设置和拆卸成本(用户空间设置是非常小的,但可能有隐藏的东西)。那么我们试试
n=100亿:~/dev/perf-test$ perf stat ./perf-test-nop 10
Performance counter stats for './perf-test-nop 10':
2907.748482 task-clock (msec) # 1.000 CPUs utilized
3 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
2 page-faults # 0.001 K/sec
10,012,820,060 cycles # 3.443 GHz
40,004,878,385 instructions # 4.00 insns per cycle
10,001,036,040 branches # 3439.443 M/sec
4,960 branch-misses # 0.00% of all branches
2.908176097 seconds time elapsed
现在有大约490万个额外的指令,比之前增加了10倍,与循环计数的增加成比例。您可以尝试各种计数器-所有与CPU相关的计数器都显示类似的比例增加。为了保持简单,让我们重点关注指令计数。使用“:u”和“:k”后缀分别测量用户和内核计数,显示在内核中产生的计数几乎占所有额外事件的比例:
~/dev/perf-test$ perf stat -e instructions:u,instructions:k ./perf-test-nop 1
Performance counter stats for './perf-test-nop 1':
4,000,000,092 instructions:u
388,958 instructions:k
0.301323626 seconds time elapsed
非常好。在这389,050个额外指令中,有99.98%(388,958个)是在内核中产生的。
好的,但这给我们留下了什么?这只是一个微不足道的CPU绑定循环。它没有进行任何系统调用,也没有访问内存(尽管可能会通过页面故障机制间接调用内核)。为什么内核代表我的应用程序执行指令?
这似乎不是由于上下文切换或CPU迁移引起的,因为这些事件的数量接近于零,而且无论如何,“额外”指令计数都不与发生更多这些事件的运行相关。
事实上,额外的内核指令数量与循环次数非常平稳。以下是(十亿级别的)循环迭代与内核指令的图表:
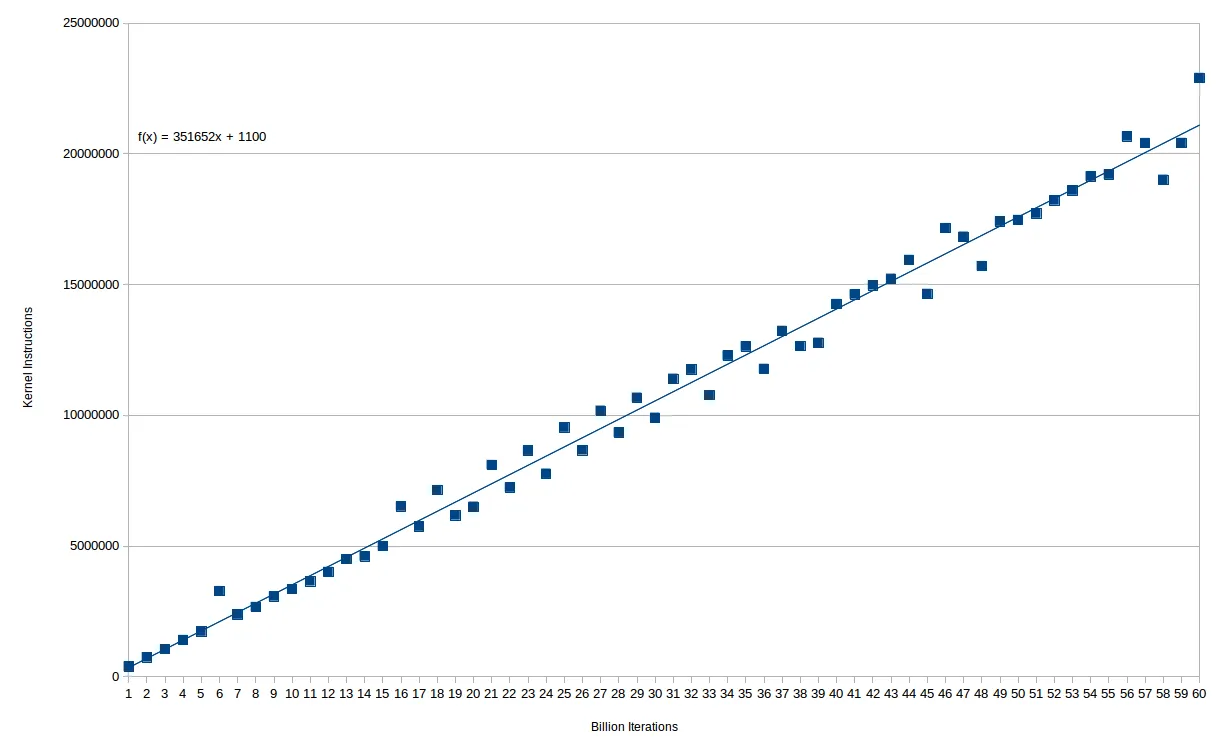
最后,我注意到执行的内核指令数量似乎与运行时间1(或CPU时间)成正比,而不是与执行的指令数量成正比。为了测试这一点,我使用了一个类似的程序,但用一个
nop指令替换了一个具有大约40个周期延迟的idiv(删除了一些不相关的行)。~/dev/perf-test$ perf stat ./perf-test-div 10
Performance counter stats for './perf-test-div 10':
41,768,314,396 cycles # 3.430 GHz
4,014,826,989 instructions # 0.10 insns per cycle
1,002,957,543 branches # 82.369 M/sec
12.177372636 seconds time elapsed
在这里,我们花费了大约42亿个周期来完成10亿次迭代,并且我们有大约1480万个额外的指令。相比之下,使用nop执行相同的10亿次循环只有大约40万个额外指令。如果我们将其与需要大约相同数量的cycles(40亿次迭代)的nop循环进行比较,我们会看到几乎完全相同数量的额外指令:
~/dev/perf-test$ perf stat ./perf-test-nop 41
Performance counter stats for './perf-test-nop 41':
41,145,332,629 cycles # 3.425
164,013,912,324 instructions # 3.99 insns per cycle
41,002,424,948 branches # 3412.968 M/sec
12.013355313 seconds time elapsed
这个内核中神秘的工作是什么情况?
1 在这里,我使用“时间”和“周期”这些术语基本上是可以互换的。CPU在这些测试期间全速运行,因此除了一些涡轮增压相关的热效应外,周期与时间成正比。
perf开销的代价。我猜测perf将HW计数器添加到64位软件总数中,只会在实际上下文切换时发生,而不是在IRQ“顶半部”处理程序中发生。 - Peter Cordesperf实际交互的信息很少。你是否错过了“...通过虚拟化硬件计数器,...”之后的一些文本? - BeeOnRope