这是我在Skylake上找到的与同一循环相关的内容。所有的代码都在github上,您可以用自己的硬件进行测试。点击此处
我观察到基于对齐方式有三个不同的性能水平,而OP只看到两个主要的性能水平。这些水平非常明显和可重复2:
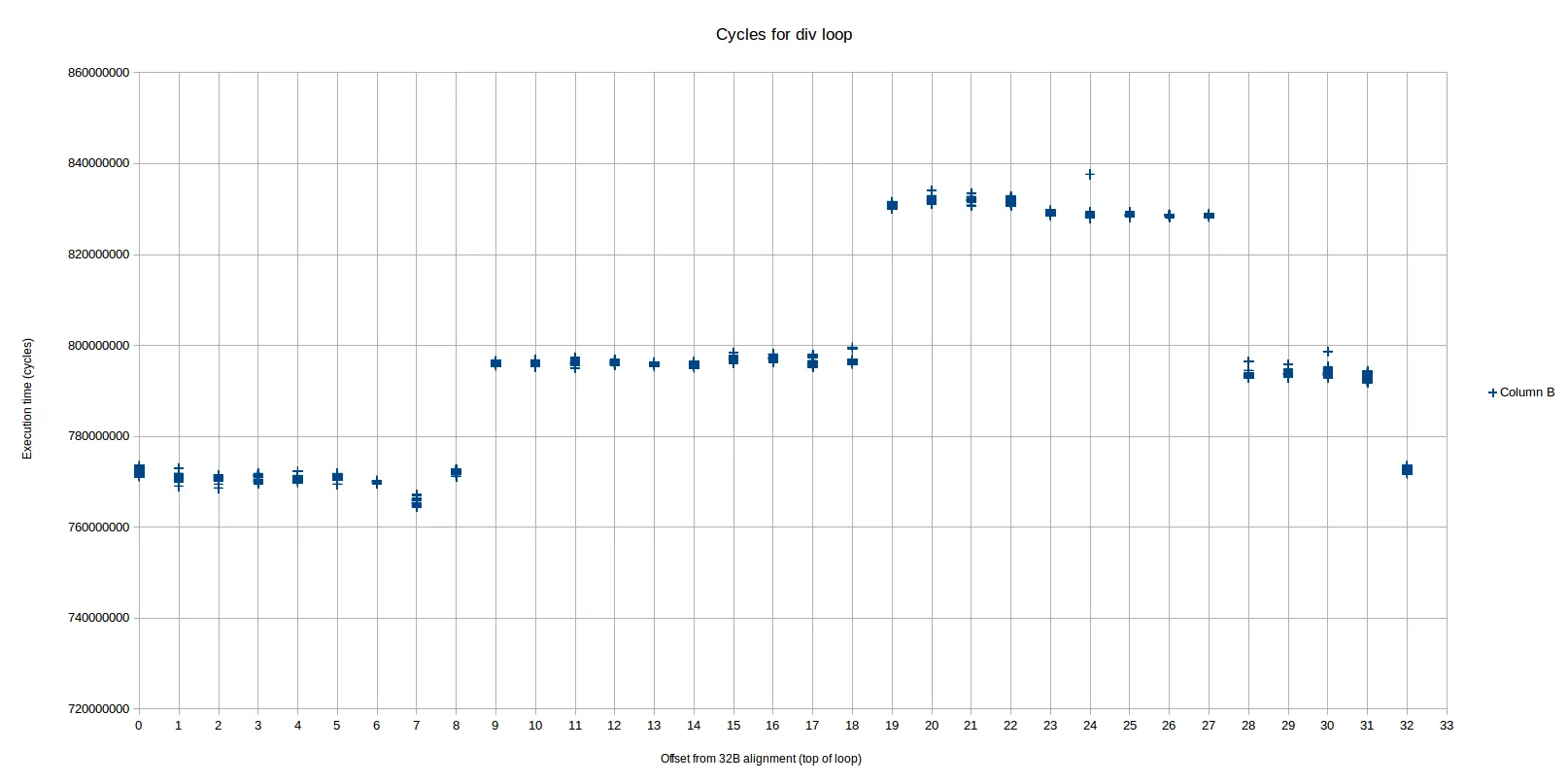
我们可以从左到右将其分别称为区域1、2和3(区域2由跨越区域3的两个部分组成)。最快的区域(1)是从偏移0到8,中间(2)区域是从9-18和28-31,最慢的(3)是从19-27。 每个区域之间的差异接近或等于每次迭代的1个周期。
根据性能计数器,最快的区域与其他两个区域非常不同:
- 所有指令都是从Legacy Decoder传递的,而不是从DSB1传递的。
- 每次循环迭代都有恰好2个解码器<->微码开关(idq_ms_switches)。
另一方面,两个较慢的区域非常相似:
- 所有指令都是从DSB(uop高速缓存)传递的,而不是从Legacy Decoder传递的。
- 每次循环迭代都有恰好3个解码器<->微码开关。
从最快区域到中间区域的转变,随着偏移量从8变为9,正好对应于由于对齐问题而开始符合uop缓冲区的循环。您可以按照Peter在他的答案中所做的方式进行精确计算:
偏移量为8:
LSD? <_start.L37>:
ab 1 4000a8: 66 0f ef c0 pxor xmm0,xmm0
ab 1 4000ac: f2 48 0f 2a c1 cvtsi2sd xmm0,rcx
ab 1 4000b1: 66 0f 2e f0 ucomisd xmm6,xmm0
ab 1 4000b5: 72 21 jb 4000d8 <_start.L36>
ab 2 4000b7: 31 d2 xor edx,edx
ab 2 4000b9: 48 89 d8 mov rax,rbx
ab 3 4000bc: 48 f7 f1 div rcx
!!!! 4000bf: 48 85 d2 test rdx,rdx
4000c2: 74 0d je 4000d1 <_start.L30>
4000c4: 48 83 c1 01 add rcx,0x1
4000c8: 79 de jns 4000a8 <_start.L37>
在第一列中,我已经注释了每个指令的uops如何进入uop缓存。"ab 1"表示它们进入与地址类似的集合中,例如...???a?或...???b?(每个集合覆盖32个字节,即0x20),而1表示第1路(最多3路)。
到了!!!这一点,这就超出了uop缓存的限制,因为test指令没有地方可以去,所有3条路都被占用了。
另一方面,让我们看看偏移量为9的情况:
00000000004000a9 <_start.L37>:
ab 1 4000a9: 66 0f ef c0 pxor xmm0,xmm0
ab 1 4000ad: f2 48 0f 2a c1 cvtsi2sd xmm0,rcx
ab 1 4000b2: 66 0f 2e f0 ucomisd xmm6,xmm0
ab 1 4000b6: 72 21 jb 4000d9 <_start.L36>
ab 2 4000b8: 31 d2 xor edx,edx
ab 2 4000ba: 48 89 d8 mov rax,rbx
ab 3 4000bd: 48 f7 f1 div rcx
cd 1 4000c0: 48 85 d2 test rdx,rdx
cd 1 4000c3: 74 0d je 4000d2 <_start.L30>
cd 1 4000c5: 48 83 c1 01 add rcx,0x1
cd 1 4000c9: 79 de jns 4000a9 <_start.L37>
现在没问题了!test指令已滑入下一个 32B 行(cd 行),因此一切都适合于 UOP 缓存。
所以这解释了为什么 MITE 和 DSB 之间的内容会发生变化,但是它并没有解释为什么 MITE 路径更快。我尝试了一些简单的循环测试,例如在循环中使用 div 指令,您可以使用更简单的循环来重现这种情况,而不需要使用任何浮点数操作。这很奇怪并且对您在循环中放置的其他随机元素很敏感。
例如,这个循环在传统解码器中执行速度也比 DSB 更快:
ALIGN 32
<add some nops here to swtich between DSB and MITE>
.top:
add r8, r9
xor eax, eax
div rbx
xor edx, edx
times 5 add eax, eax
dec rcx
jnz .top
在那个循环中,加入无意义的add r8, r9指令,并不真正与循环的其余部分互动,使MITE版本的速度提高了(但不是DSB版本)。
因此,我认为区域1和区域2、3之间的差异是由前者在传统解码器中执行(奇怪的是,这使它更快)。
接下来,我们也来看一下从偏移量18到偏移量19的转换(即区域2结束并开始区域3):
偏移量18:
00000000004000b2 <_start.L37>:
ab 1 4000b2: 66 0f ef c0 pxor xmm0,xmm0
ab 1 4000b6: f2 48 0f 2a c1 cvtsi2sd xmm0,rcx
ab 1 4000bb: 66 0f 2e f0 ucomisd xmm6,xmm0
ab 1 4000bf: 72 21 jb 4000e2 <_start.L36>
cd 1 4000c1: 31 d2 xor edx,edx
cd 1 4000c3: 48 89 d8 mov rax,rbx
cd 2 4000c6: 48 f7 f1 div rcx
cd 3 4000c9: 48 85 d2 test rdx,rdx
cd 3 4000cc: 74 0d je 4000db <_start.L30>
cd 3 4000ce: 48 83 c1 01 add rcx,0x1
cd 3 4000d2: 79 de jns 4000b2 <_start.L37>
偏移量 19:
00000000004000b3 <_start.L37>:
ab 1 4000b3: 66 0f ef c0 pxor xmm0,xmm0
ab 1 4000b7: f2 48 0f 2a c1 cvtsi2sd xmm0,rcx
ab 1 4000bc: 66 0f 2e f0 ucomisd xmm6,xmm0
cd 1 4000c0: 72 21 jb 4000e3 <_start.L36>
cd 1 4000c2: 31 d2 xor edx,edx
cd 1 4000c4: 48 89 d8 mov rax,rbx
cd 2 4000c7: 48 f7 f1 div rcx
cd 3 4000ca: 48 85 d2 test rdx,rdx
cd 3 4000cd: 74 0d je 4000dc <_start.L30>
cd 3 4000cf: 48 83 c1 01 add rcx,0x1
cd 3 4000d3: 79 de jns 4000b3 <_start.L37>
我看到唯一的区别在于偏移量为18的情况下前4条指令适配到ab缓存行,而偏移量为19的情况下只有3条。如果我们假设DSB只能从一个缓存集向IDQ传递uops,这意味着在某个时刻,在偏移量18的场景中可能会发出并执行一个uop,比在偏移量19的场景中早一个周期(例如,假设IDQ为空)。根据所在uop流的上下文准确跳转到哪个端口,这可能会延迟循环一个周期。实际上,区域2和3之间的差异约为1个周期(在误差范围内)。
因此,我认为我们可以说,2和3之间的差异可能是由于uop缓存对齐 - 区域2比3具有稍好的对齐方式,以在一个周期内更早地发出一个额外的uop。
关于我检查但未被证明是导致减速的可能原因的一些附加说明:
尽管DSB模式(区域2和3)具有3个微代码开关,而MITE路径(区域1)是2个,但似乎并不会直接导致减速。特别地,使用div的简单循环执行相同的周期计数,但仍然显示DSB和MITE路径分别为3和2个开关。因此这是正常的,不直接暗示减速。
两条路径执行基本相同数量的uops,并且特别地,具有相同数量的由微代码序列器生成的uops。因此,不像在不同区域中有更多的总工作量。
在各种级别的缓存未命中(非常低,如预期)中,分支预测错误率(本质上为零3),或者我检查的任何其他类型的惩罚或异常情况中,实际上没有太大的差异。
真正有成果的是查看各个区域内执行单元使用的模式。以下是每周期执行的uop分布和一些停顿指标:
+----------------------------+----------+----------+----------+
| | Region 1 | Region 2 | Region 3 |
+----------------------------+----------+----------+----------+
| cycles: | 7.7e8 | 8.0e8 | 8.3e8 |
| uops_executed_stall_cycles | 18
| exe_activity_1_ports_util | 31
| exe_activity_2_ports_util | 29
| exe_activity_3_ports_util | 12
| exe_activity_4_ports_util | 10
+----------------------------+----------+----------+----------+
我尝试了几种不同的偏移值,结果在每个区域内是一致的,但在不同的区域之间,结果却相当不同。特别是在区域1中,停顿周期(没有执行uop的周期)较少。非停顿周期也存在显著的差异,尽管没有明显的“更好”或“更差”的趋势。例如,区域1有许多执行4个uop的周期(10% vs 3%或4%),但其他区域往往通过更多执行3个uop的周期和很少执行1个uop的周期来弥补这一点。
上述执行分布中的UPC4差异充分解释了性能差异(这可能是一个类似自证明的道理,因为我们已经确认它们之间的uop计数是相同的)。
让我们看看toplev.py对此有何看法...(省略结果)。
好吧,toplev建议主要瓶颈是前端(50+%)。我认为您不能相信这一点,因为它计算FE-bound的方式在长字符串的微码指令情况下似乎有问题。 FE-bound基于frontend_retired.latency_ge_8,定义为:
在前端在8个周期内未传递uops的情况下获取的退役指令,其中未被后端阻塞打断。 (支持PEBS)
通常这很有道理。您正在计算由于前端未传递周期而延迟的指令。 “不受后端停顿中断”的条件确保在前端未传递uops仅因为后端无法接受它们时(例如,当RS已满时,因为后端正在执行一些低吞吐量的指令)不会触发此操作。
对于div指令而言,似乎即使是非常简单的循环也会出现问题:
FE Frontend_Bound: 57.59 % [100.00%]
BAD Bad_Speculation: 0.01 %below [100.00%]
BE Backend_Bound: 0.11 %below [100.00%]
RET Retiring: 42.28 %below [100.00%]
换句话说,瓶颈只存在于前端(“退役”不是瓶颈,它代表有用的工作)。显然,这样的循环由前端轻松处理,而实际上被后端的能力限制,可以咀嚼所有由
操作生成的UOP。Toplev可能会非常错误,因为(1)微代码序列器提供的UOPS可能没有计入
frontend_retired.latency...计数器中,因此每个
div操作都会导致该事件计算所有后续指令(即使CPU在那段时间内很忙-没有真正的停顿),或者(2)微代码序列器可能会将所有UPS基本上一次性提供,并将~36 UOPs猛烈地抛进IDQ,此时它不再提供任何UOP,直到
div完成为止,或类似于此类的东西。
尽管如此,我们可以查看toplev的低级别提示:
toplev在区域1和区域2和3之间所述的主要区别是后两个区域的ms_switches的惩罚增加了(因为它们每次迭代都产生3,而遗留路径只产生2的开销。在内部,toplev为这些开关估算前端的2个周期惩罚。当然,这些惩罚是否实际上会减慢任何东西取决于指令队列和其他因素的复杂方式。如上所述,具有div的简单循环不显示DSB和MITE路径之间的任何差异,具有其他指令的循环则会显示差异。因此,可能是额外的切换泡沫在更简单的循环中被吸收了(其中由div产生的所有UOP的后端处理是主要因素),但是一旦您在循环中添加一些其他工作时,切换就会成为至少在div和非div 工作之间的过渡期间成为一个因素。
因此,我认为结论是div指令与前端uop流和后端执行的相互作用还没有完全理解。我们知道它涉及大量UOPS,其中许多来自MITE/DSB(似乎每个div有4个UOPS)和微代码序列器(似乎每个div有~32个UOPS,尽管它随着对div操作的不同输入值而改变)-但我们不知道那些UOPS是什么(我们可以看到它们的端口分配,尽管如此)。所有这些都使得行为相当不透明,但我认为它可能是由于MS开关瓶颈前端,或UOP传递流程中微小的差异导致不同的调度决策最终使MITE顺序成为主导。
1.当然,大多数uops根本不是从传统解码器或DSB传送的,而是由微代码序列器(ms)传送的。因此,我们粗略地谈论传递的指令,而不是UOPS。
2 注意这里的x轴是“偏移字节距离32B对齐”的意思。也就是说,0表示循环顶部(标签.L37)对齐到32B边界,5表示循环在32B边界以下5个字节处开始(使用nop进行填充),以此类推。因此,我的填充字节和偏移量是相同的。如果我正确理解了,OP使用了另一种偏移的含义:他的1个字节填充导致偏移为0。因此,你需要从OP的填充值中减去1来得到我的偏移值。
3 实际上,对于一个typical测试,即prime=1000000000000037,分支预测率为~99.999997%,整个运行中仅出现了3次错误的预测分支(很可能是在第一次循环通过和最后一次迭代中发生)。
4 UPC,即每个周期的微操作数 - 一种与IPC类似的度量方式,当我们详细研究微操作流时,它更加精确。在这种情况下,我们已经知道所有对齐变化的微操作数量是相同的,因此UPC和IPC将直接成比例。
 从没有填充的
从没有填充的
dpps,我的计数器显示有70万个 uops,其中:idq.dsb_uops 499966284和idq.ms_dsb_uops 200000595。 - Iwillnotexist Idonotexistloop: div rcx; dec rcx; jne loop循环,并将零除以计数器进行了 1 亿次迭代。这造成的损害是 37 亿个微操作,其中 32 亿个由微代码序列器馈入 DSB,0.5 亿个直接来自 DSB,没有来自 LSD。 - Iwillnotexist Idonotexistdec+jne,除法的前4个uop也存在于DSB中,但其余的32个uop则被MS所限制。再加上Haswell的除法是36个uop,并均匀分布在p0 p1 p5 p6(所有这些都有整数ALU,其中p6是预测取的分支的端口),这让我想到,在内部,除法执行高基数、每次迭代4个uop的循环,每次产生约8位商。 - Iwillnotexist Idonotexistrep movs启动过程)不受通常的分支预测硬件的动态分支预测影响(这就是为什么它即使在重复使用时也具有如此高的启动开销,正如原始P6 rep-string实现的设计者Andy Glew解释的那样)。据我所知,它们没有错误预测,因此也许微码分支是特殊的,而且没有被推测执行?显然它们可以有效地循环。 - Peter Cordes