我已经实现了一个简单的线性探测哈希映射,使用结构体数组内存布局。该结构体包含键、值和指示条目是否有效的标志。默认情况下,由于键和值是64位整数,因此编译器会对该结构体进行填充,但条目只占用8个布尔值。因此,我还尝试过打包结构体,以牺牲未对齐访问的代价。我希望从打包/未对齐版本中获得更好的性能,因为它具有更高的内存密度(我们不会浪费带宽传输填充字节)。
在Intel Xeon Gold 5220S CPU上进行基准测试时(单线程,gcc 11.2,-O3和-march=native),我发现填充版本和未对齐版本之间没有性能差异。然而,在AMD EPYC 7742 CPU上(相同的设置),我发现未对齐和填充之间存在性能差异。下面是一个图表,显示了哈希映射负载因子为25%和50%时,不同成功查询率(x轴为0,25,50,75,100)的结果: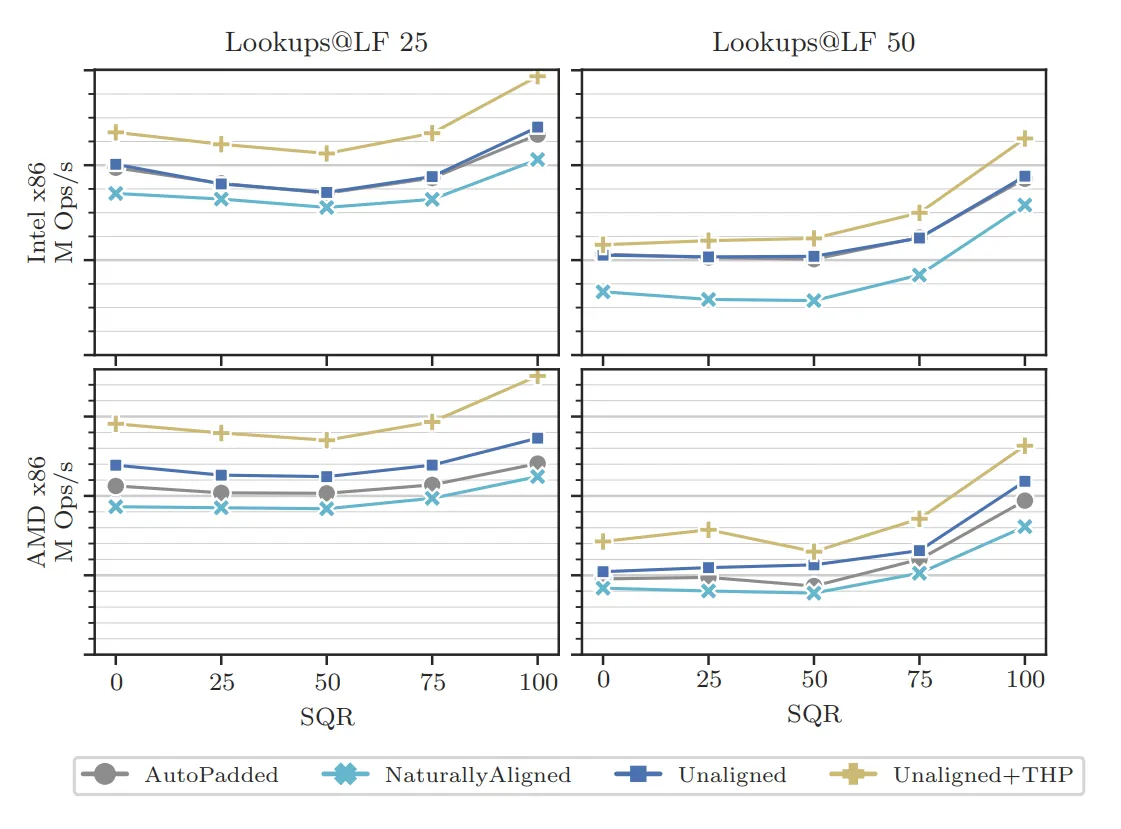 如您所见,在Intel上,灰色和蓝色(圆形和正方形)线条几乎重叠,结构体打包的好处微不足道。然而,在AMD上,表示未对齐/填充结构的线路始终较高,即我们有更高的吞吐量。
如您所见,在Intel上,灰色和蓝色(圆形和正方形)线条几乎重叠,结构体打包的好处微不足道。然而,在AMD上,表示未对齐/填充结构的线路始终较高,即我们有更高的吞吐量。
为了调查这个问题,我尝试构建一个更小的微基准测试。在这个微基准测试中,我们执行类似的基准测试,但没有哈希映射查找逻辑(即,我们只选择数组中的随机索引并稍微前进)。请在此处找到基准测试:
在运行基准测试时,我选择重复次数为3,步进值为5,即编译和运行后,您需要输入3(并按回车键),然后输入5并按回车/换行键。我更新了源代码以(a)避免编译器进行循环展开,因为重复/前进是硬编码的,(b)切换到指向该向量的指针,因为它更接近哈希映射正在执行的操作。
在英特尔CPU上,我获得:
填充运行时间(毫秒):13204 非对齐运行时间(毫秒):12185
在AMD CPU上,我获得:
填充运行时间(毫秒):28432 非对齐运行时间(毫秒):22926
因此,虽然在这个微基准测试中,英特尔仍然从不对齐的访问中获益一点,但对于 AMD CPU 来说,绝对和相对的改进都更高。我无法解释这一点。通常情况下,根据我从相关 SO 线程中学到的,只要保持在单个缓存行内,单个成员的不对齐访问与对齐访问一样昂贵。同时,在 (1) 中引用了 (2),它声称 缓存获取宽度 可以与缓存行大小不同。然而,除了 Linus Torvalds 的邮件之外,我找不到任何其他关于处理器缓存获取宽度的文档,尤其是针对我的两个具体 CPU,以便弄清楚这是否可能与此有关。
在Intel Xeon Gold 5220S CPU上进行基准测试时(单线程,gcc 11.2,-O3和-march=native),我发现填充版本和未对齐版本之间没有性能差异。然而,在AMD EPYC 7742 CPU上(相同的设置),我发现未对齐和填充之间存在性能差异。下面是一个图表,显示了哈希映射负载因子为25%和50%时,不同成功查询率(x轴为0,25,50,75,100)的结果:
如您所见,在Intel上,灰色和蓝色(圆形和正方形)线条几乎重叠,结构体打包的好处微不足道。然而,在AMD上,表示未对齐/填充结构的线路始终较高,即我们有更高的吞吐量。为了调查这个问题,我尝试构建一个更小的微基准测试。在这个微基准测试中,我们执行类似的基准测试,但没有哈希映射查找逻辑(即,我们只选择数组中的随机索引并稍微前进)。请在此处找到基准测试:
#include <atomic>
#include <chrono>
#include <cstdint>
#include <iostream>
#include <random>
#include <vector>
void ClobberMemory() { std::atomic_signal_fence(std::memory_order_acq_rel); }
template <typename T>
void doNotOptimize(T const& val) {
asm volatile("" : : "r,m"(val) : "memory");
}
struct PaddedStruct {
uint64_t key;
uint64_t value;
bool is_valid;
PaddedStruct() { reset(); }
void reset() {
key = uint64_t{};
value = uint64_t{};
is_valid = 0;
}
};
struct PackedStruct {
uint64_t key;
uint64_t value;
uint8_t is_valid;
PackedStruct() { reset(); }
void reset() {
key = uint64_t{};
value = uint64_t{};
is_valid = 0;
}
} __attribute__((__packed__));
int main() {
const uint64_t size = 134217728;
uint16_t repetitions = 0;
uint16_t advancement = 0;
std::cin >> repetitions;
std::cout << "Got " << repetitions << std::endl;
std::cin >> advancement;
std::cout << "Got " << advancement << std::endl;
std::cout << "Initializing." << std::endl;
std::vector<PaddedStruct> padded(size);
std::vector<PackedStruct> unaligned(size);
std::vector<uint64_t> queries(size);
// Initialize the structs with random values + prefault
std::random_device rd;
std::mt19937 gen{rd()};
std::uniform_int_distribution<uint64_t> dist{0, 0xDEADBEEF};
std::uniform_int_distribution<uint64_t> dist2{0, size - advancement - 1};
for (uint64_t i = 0; i < padded.size(); ++i) {
padded[i].key = dist(gen);
padded[i].value = dist(gen);
padded[i].is_valid = 1;
}
for (uint64_t i = 0; i < unaligned.size(); ++i) {
unaligned[i].key = padded[i].key;
unaligned[i].value = padded[i].value;
unaligned[i].is_valid = 1;
}
for (uint64_t i = 0; i < unaligned.size(); ++i) {
queries[i] = dist2(gen);
}
std::cout << "Running benchmark." << std::endl;
ClobberMemory();
auto start_padded = std::chrono::high_resolution_clock::now();
PaddedStruct* padded_ptr = nullptr;
uint64_t sum = 0;
for (uint16_t j = 0; j < repetitions; j++) {
for (const uint64_t& query : queries) {
for (uint16_t i = 0; i < advancement; i++) {
padded_ptr = &padded[query + i];
if (padded_ptr->is_valid) [[likely]] {
sum += padded_ptr->value;
}
}
doNotOptimize(sum);
}
}
ClobberMemory();
auto end_padded = std::chrono::high_resolution_clock::now();
uint64_t padded_runtime = static_cast<uint64_t>(std::chrono::duration_cast<std::chrono::milliseconds>(end_padded - start_padded).count());
std::cout << "Padded Runtime (ms): " << padded_runtime << " (sum = " << sum << ")" << std::endl; // print sum to avoid that it gets optimized out
ClobberMemory();
auto start_unaligned = std::chrono::high_resolution_clock::now();
uint64_t sum2 = 0;
PackedStruct* packed_ptr = nullptr;
for (uint16_t j = 0; j < repetitions; j++) {
for (const uint64_t& query : queries) {
for (uint16_t i = 0; i < advancement; i++) {
packed_ptr = &unaligned[query + i];
if (packed_ptr->is_valid) [[likely]] {
sum2 += packed_ptr->value;
}
}
doNotOptimize(sum2);
}
}
ClobberMemory();
auto end_unaligned = std::chrono::high_resolution_clock::now();
uint64_t unaligned_runtime = static_cast<uint64_t>(std::chrono::duration_cast<std::chrono::milliseconds>(end_unaligned - start_unaligned).count());
std::cout << "Unaligned Runtime (ms): " << unaligned_runtime << " (sum = " << sum2 << ")" << std::endl;
}
在运行基准测试时,我选择重复次数为3,步进值为5,即编译和运行后,您需要输入3(并按回车键),然后输入5并按回车/换行键。我更新了源代码以(a)避免编译器进行循环展开,因为重复/前进是硬编码的,(b)切换到指向该向量的指针,因为它更接近哈希映射正在执行的操作。
在英特尔CPU上,我获得:
填充运行时间(毫秒):13204 非对齐运行时间(毫秒):12185
在AMD CPU上,我获得:
填充运行时间(毫秒):28432 非对齐运行时间(毫秒):22926
因此,虽然在这个微基准测试中,英特尔仍然从不对齐的访问中获益一点,但对于 AMD CPU 来说,绝对和相对的改进都更高。我无法解释这一点。通常情况下,根据我从相关 SO 线程中学到的,只要保持在单个缓存行内,单个成员的不对齐访问与对齐访问一样昂贵。同时,在 (1) 中引用了 (2),它声称 缓存获取宽度 可以与缓存行大小不同。然而,除了 Linus Torvalds 的邮件之外,我找不到任何其他关于处理器缓存获取宽度的文档,尤其是针对我的两个具体 CPU,以便弄清楚这是否可能与此有关。
有人知道为什么 AMD CPU 从结构体打包中受益更多吗?如果涉及减少内存带宽消耗,我应该能够看到两个 CPU 上的效果。如果带宽使用类似,则我不理解这里可能导致差异的原因。
非常感谢你。
(1) 相关 SO 线程:如何在 x86_64 上准确测试未对齐的访问速度?
(2) https://www.realworldtech.com/forum/?threadid=168200&curpostid=168779
(2) https://www.realworldtech.com/forum/?threadid=168200&curpostid=168779
perf结果以及关于 如何在 x86_64 上准确基准测试非对齐访问速度? 的写作)。我认为 BeeOnRope 和我主要测试了标量和可能是 XMM,但这对 YMM 也很熟悉。4k 分裂的吞吐量较低,大约每 3.8c 1 次,但在 SKL 及更高版本上并不像 Haswell 那样完全失败。 - Peter Cordesperf调试,并发现在两个系统上,非对齐版本需要更多的指令来访问结构成员,但需要更少的内存加载。然而,由于AMD系统实际上具有更高的单线程内存读取带宽,我仍然不知道如何解释这一现象。 - Maxbit