我希望能够从分层抽样设计中估计均值和总数,其中在每个分层中使用了单阶段群集抽样。我相信我已经正确使用“survey”包的“svydesign()”函数来规定了设计方案。但我不确定如何正确指定分层权重。
下面是示例代码。我使用“weights=”参数提供未经调整的分层权重。我预期“svytotal()”的估计值和SE将等于分层权重之和(例如,在本示例中为70)乘以“svymean()”的估计值和SE。但实际上,估计值的差异因子为530(这是计数数据中所有元素的分层权重之和),而SE的差异因子为898(???)。我的问题是:(1)我如何向“svydesign()”提供我的三个分层权重,使其理解?(2)为什么“svytotal()”和“svymean()”的估计值和SE没有按同样的因子进行差异?
这将产生以下输出:
下面是示例代码。我使用“weights=”参数提供未经调整的分层权重。我预期“svytotal()”的估计值和SE将等于分层权重之和(例如,在本示例中为70)乘以“svymean()”的估计值和SE。但实际上,估计值的差异因子为530(这是计数数据中所有元素的分层权重之和),而SE的差异因子为898(???)。我的问题是:(1)我如何向“svydesign()”提供我的三个分层权重,使其理解?(2)为什么“svytotal()”和“svymean()”的估计值和SE没有按同样的因子进行差异?
library(survey)
# example data from a stratified sampling design in which
# single stage cluster sampling is used in each stratum
counts <- data.frame(
Stratum=rep(c("A", "B", "C"), c(5, 8, 8)),
Cluster=rep(1:8, c(3, 2, 3, 2, 3, 2, 3, 3)),
Element=c(1, 2, 3, 1, 2, 1, 2, 3, 1, 2, 1, 2, 3, 1, 2, 1, 2, 3, 1, 2, 3),
Count = 1:21
)
# stratum weights
weights <- data.frame(
Stratum=c("A", "B", "C"),
W=c(10, 20, 40)
)
# combine counts and weights
both <- merge(counts, weights)
# estimate mean and total count
D <- svydesign(id=~Cluster, strata=~Stratum, weights=~W, data=both)
a <- svymean(~Count, D)
b <- svytotal(~Count, D)
sum(weights$W) # 70
sum(both$W) # 530
coef(b)/coef(a) # 530
SE(b)/SE(a) # 898.4308
第一次更新
我正在添加一个图表来帮助解释我的设计。整个人口是一个已知面积的湖泊(例如,70公顷)。层有已知的面积(10、20和40公顷)。每层分配的簇数不成比例。此外,与可能被抽样的数量相比,这些簇非常小,因此有限人口校正为FPC = 1。
我想计算每单位面积的总体平均值和SE,并且总数等于70倍这个平均值和SE。
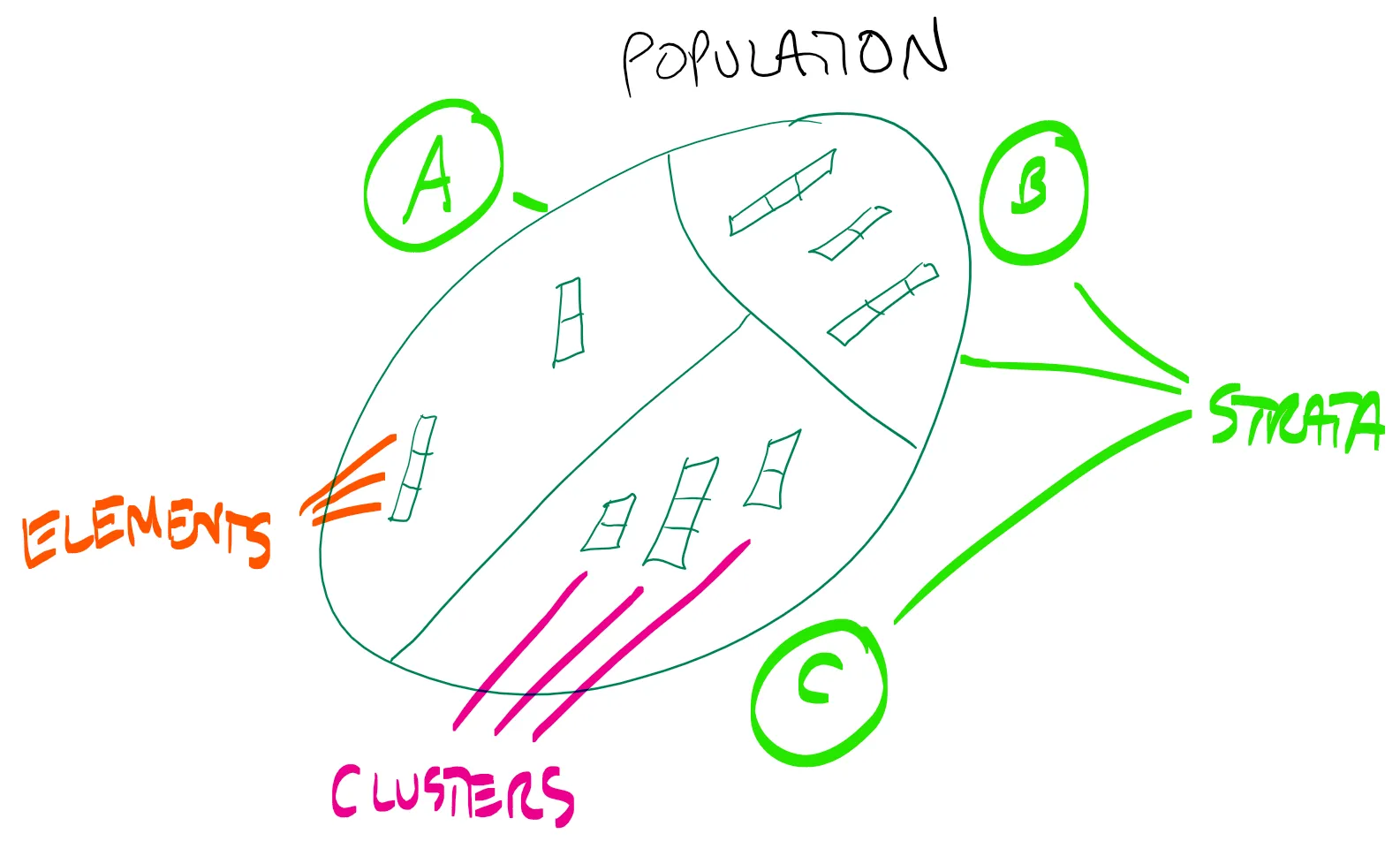
第二次更新
我编写了代码来从头开始进行计算。 我得到了一个总估计值为920,标准误为61.6。
library(survey)
library(tidyverse)
# example data from a stratified sampling design in which
# single stage cluster sampling is used in each stratum
counts <- data.frame(
Stratum=rep(c("A", "B", "C"), c(5, 8, 8)),
Cluster=rep(1:8, c(3, 2, 3, 2, 3, 2, 3, 3)),
Element=c(1, 2, 3, 1, 2, 1, 2, 3, 1, 2, 1, 2, 3, 1, 2, 1, 2, 3, 1, 2, 3),
Count = c(5:1, 6:21)
)
# stratum weights
areas <- data.frame(
Stratum=c("A", "B", "C"),
A_h=c(10, 20, 40)
)
# calculate cluster means
step1 <- counts %>%
group_by(Stratum, Cluster) %>%
summarise(P_hi = sum(Count), m_hi=n())
step2 <- step1 %>%
group_by(Stratum) %>%
summarise(
ybar_h = sum(P_hi) / sum(m_hi),
n_h = n(),
sh.numerator = sum((P_hi - ybar_h*m_hi)^2),
mbar_h = mean(m_hi)
) %>%
mutate(
S_ybar_h = 1 / mbar_h * sqrt( sh.numerator / (n_h * (n_h-1)) )
)
# now expand up to strata
step3 <- step2 %>%
left_join(areas) %>%
mutate(
W_h = A_h / sum(A_h)
) %>%
summarise(
A = sum(A_h),
ybar_strat = sum(W_h * ybar_h),
S_ybar_strat = sum(W_h * S_ybar_h / sqrt(n_h))
) %>%
mutate(
tot = A * ybar_strat,
S_tot = A * S_ybar_strat
)
step2
step3
这将产生以下输出:
> step2
# A tibble: 3 x 6
Stratum ybar_h n_h sh.numerator mbar_h S_ybar_h
<fctr> <dbl> <int> <dbl> <dbl> <dbl>
1 A 3.0 2 18.0 2.500000 1.200000
2 B 9.5 3 112.5 2.666667 1.623798
3 C 17.5 3 94.5 2.666667 1.488235
> step3
# A tibble: 1 x 5
A ybar_strat S_ybar_strat tot S_tot
<dbl> <dbl> <dbl> <dbl> <dbl>
1 70 13.14286 0.8800657 920 61.6046