我进行了一项包含138个问题的调查,其中只有少数问题是Likert类型的,有些问题有不同的量表。
我一直试图在R中使用Likert包来分析和图形化呈现数据,但是我非常难以理解它的任何部分。
我已经浏览了“演示文稿”,但只有在您已经知道该软件包的情况下才有用。它不解释在能够应用Likert包之前必须采取的任何步骤、可以实际应用于软件包的内容、如何重新命名变量等等。你只会得到一堆代码和一个兔子洞,试图弄清楚所有这些。
我已经搜索谷歌寻找使用Likert包的逐步指南,但什么也没找到。
请问有人能够指导我一个指南或至少提供我必须在我的数据框架中采取的步骤,才能尝试使用Likert包吗?
我希望使用此软件包将我的几列(包含Likert响应)拟合到堆积条形图中。
一旦我确定Likert包确切接受哪些清理后的数据框架,我就应该能够遵循演示文稿...也许...
根据我的有限R知识和自己尝试弄清楚事情的情况,我已经完成了以下工作。
library(likert)
library(dplyr)
fdaff_likert <- select(f2f, RESPID, daff_rate)
fdaff_likert <- data.frame(fdaff_likert)
fdaff_likert <- likert(items=fdaff_likert[,2, drop = FALSE], nlevels = 5)
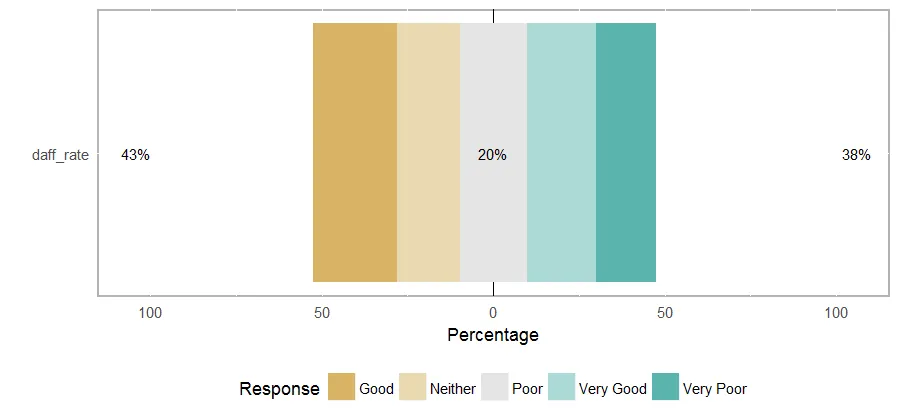
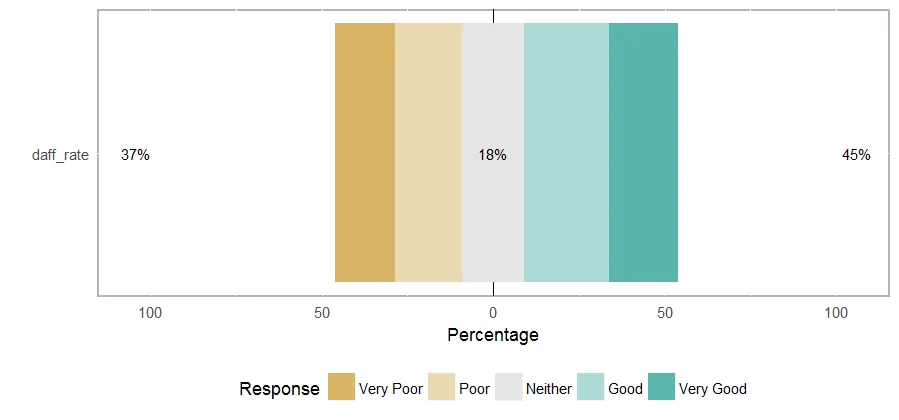
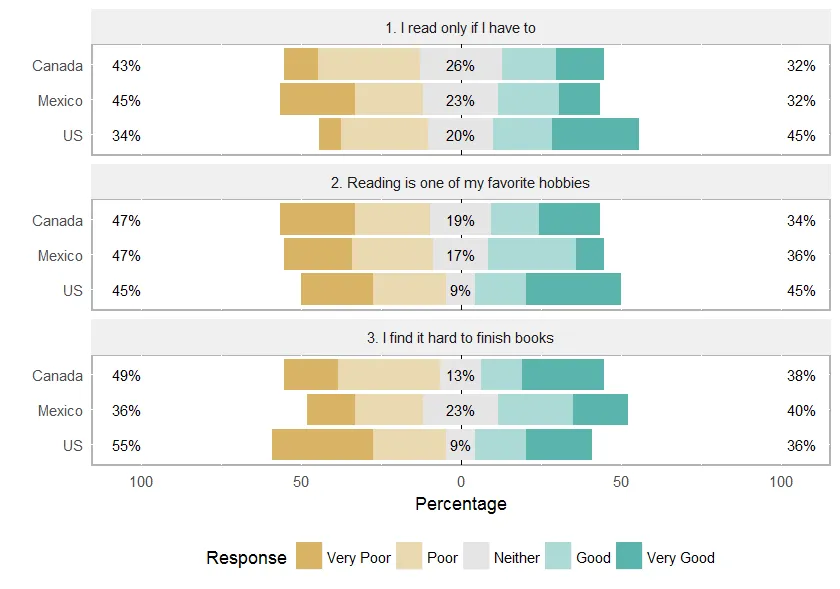
我的Likert量表的输出结果是:
summary(fdaff_likert)
Item low neutral high mean sd
1 daff_rate 9.977827 37.91574 52.10643 3.802661 1.302508
然而,情节却杂乱无章。
plot (fdaff_likert)
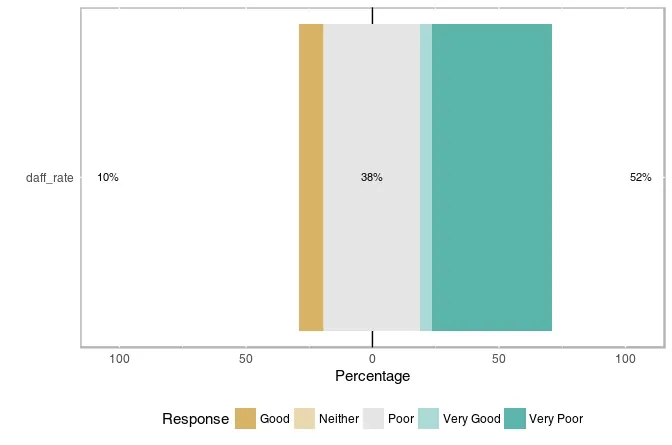
李克特量表的顺序是错乱的,并且没有正确居中。此外,如何将y轴重命名为问题?
为了进行后续分析,如何将其分成组级别(基于指定原始数据框中区域的另一列)?