我在编译以下漏洞代码时遇到了问题:
http://downloads.securityfocus.com/vulnerabilities/exploits/59846-1.c
我正在使用"gcc file.c"和"gcc -O2 file.c",但两者都导致以下错误:sorbolinux-exec.c: In function ‘sc’:
sorbolinux-exec.c:76: error: stray ‘\302’ in program
sorbolinux-exec.c:76: error: stray ‘\244’ in program
sorbolinux-exec.c:76: error: ‘t’ undeclared (first use in this function)
sorbolinux-exec.c:76: error: (Each undeclared identifier is reported only once
sorbolinux-exec.c:76: error: for each function it appears in.)
我尝试在Kali Linux和Ubuntu 10.04(Lucid Lynx)上编译它们,结果相同。
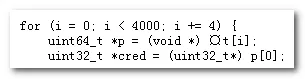
\x{200B}可以解决这个问题。 - Peter Mortensen