我一直在使用这段代码,尝试从COCO数据集生成图像的原始掩码。
dataDir='G:'
dataType='train2014'
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataType)
coco=COCO(annFile)
annFile = '{}/annotations/person_keypoints_{}.json'.format(dataDir,dataType)
coco_kps=COCO(annFile)
catIds = coco.getCatIds(catNms=['person'])
imgIds = coco.getImgIds(catIds=catIds );
imgIds = coco.getImgIds(imgIds = imgIds[0])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
I = io.imread('G:/train2014/'+img['file_name'])
plt.imshow(I); plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)
但是我得到的结果是这样的:

但是我想要的是这样的:

我如何得到每个图像的原始掩码?


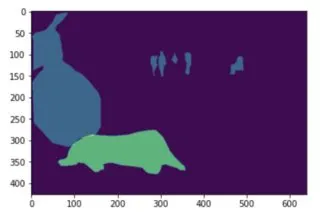


mask = coco.annToMask(anns[0]),然后从零开始循环anns将会使第一个索引重复添加两次。Doggo的值为2,而其余的为1。你不应该在循环之前声明mask,在循环内部声明更好。 - colt.exe