我有一个包含N个顶点的图表,每个顶点代表一个地方。此外,我有向量,每个用户一个,每个向量由N个系数组成,其中系数的值是在对应地方花费的秒数或0(如果未访问该地方)。
例如,对于以下图表: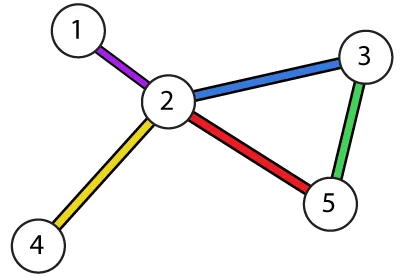 对应的向量为:
对应的向量为:
例如,对于以下图表:
对应的向量为:v1 = {100, 50, 0 30, 0}
这意味着我们花费了:
100secs at vertex 1
50secs at vertex 2 and
30secs at vertex 4
顶点 3 和 5 没有被访问过,因此为 0。
我想运行 k-means 聚类,并选择余弦距离公式 cosine_distance = 1 - cosine_similarity 作为距离的衡量标准。其中,cosine_similarity 的公式如下:
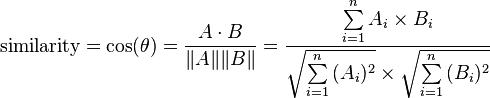
该公式可以在这里找到描述。
但我发现以下情况。假设 k=2,并且向量之一为:
v1 = {90,0,0,0,0}
c1 = {90,90,90,90,90}
c2 = {1000, 1000, 1000, 1000, 1000}
对于 (v1, c1) 和 (v1, c2),应用 cosine_distance 公式,我们得到了相同的距离,即 0.5527864045。
我认为 v1 与 c1 的相似度(距离)更高。但显然情况并非如此。
Q1. 为什么这个假设是错误的?
Q2. 对于这种情况,余弦距离是否正确?
Q3. 鉴于问题的性质,有哪些更好的距离函数可供选择?