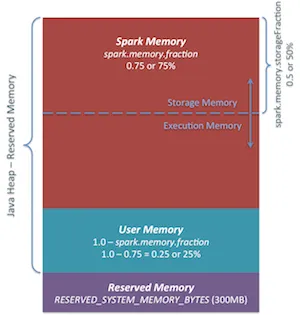
我正在尝试找到最佳方式来配置我的群集节点上的内存。然而,我认为需要进一步了解一些事情,例如spark如何跨任务处理内存等内容。
例如,假设我有3个执行器,每个执行器可以并行运行8个任务(即8个核心)。如果我有一个具有24个分区的RDD,则理论上所有分区都可以并行处理。但是,如果我们在这里放大一个执行器,这意味着每个任务都可以在内存中拥有其分区进行操作。如果没有,则意味着无法并行处理8个任务,需要进行一些调度。
因此,我得出结论,要实现真正的并行性,了解分区大小的一些想法将会有所帮助,因为这将告诉您如何调整执行器以实现真正的并行性。
例如,假设我有3个执行器,每个执行器可以并行运行8个任务(即8个核心)。如果我有一个具有24个分区的RDD,则理论上所有分区都可以并行处理。但是,如果我们在这里放大一个执行器,这意味着每个任务都可以在内存中拥有其分区进行操作。如果没有,则意味着无法并行处理8个任务,需要进行一些调度。
因此,我得出结论,要实现真正的并行性,了解分区大小的一些想法将会有所帮助,因为这将告诉您如何调整执行器以实现真正的并行性。
Q0-我只是想更好地了解一下,当一个执行器的内存不能容纳所有分区时会发生什么?有些分区会溢出到磁盘,而其他分区则在内存中进行操作吗?Spark是否为每个任务保留内存,如果检测到不足,是否安排任务?还是只会运行内存耗尽的错误?
Q1- executor内部的真正并行取决于执行器上可用的内存量吗?换句话说,我可能在群集中有8个核心,但如果我没有足够的内存一次加载8个分区的数据,则无法完全并行。
这究竟是如何工作的呢?我的意思是,Spark可能会处理更小的子集,但如果总的分区集无论如何都无法容纳内存,会发生什么?“增加分区的数量也有助于减少内存不足错误,因为这意味着Spark将对每个执行器的较小子集进行操作。”